今回から日本版(1)のデータの前処理を始めたいと思います。
まずはSIGNATEで開催されているコンペティションCOVID-19チャレンジで提供されているsignate_covid-19_datasetを使って日本の全国・都道府県別の可視化までを目指します。
signate_covid-19_datasetからSIGNATE COVID-19 Case Datasetを開くと以下のように4枚のシートを持つGoogleスプレッドシートが開きます。
今回使用したいのはこの内の罹患者統計。
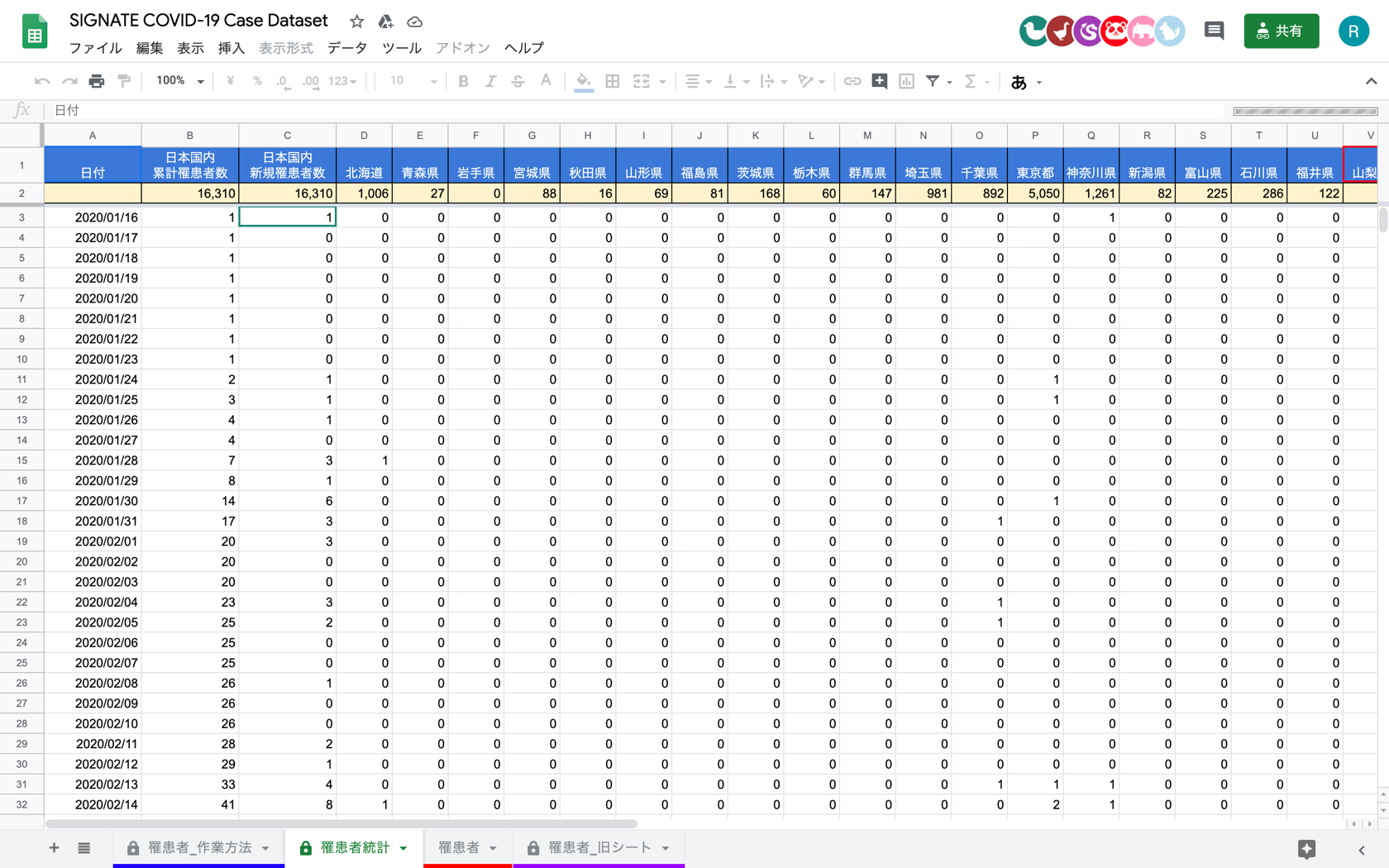
まずはこちらのシートをcsvファイルとしてダウンロードします。
ダウンロードしたデータだとSIGNATE COVID-19 Case Dataset – 罹患者統計.csvとちょっと名前が長いのでSIGNATE_COVID19.csvにリネームして使うことにします。
c19_j1 = pd.read_csv("SIGNATE_COVID19.csv" , encoding = "utf=8")
c19_j1.head()で読み込みを行うと以下のようになります。
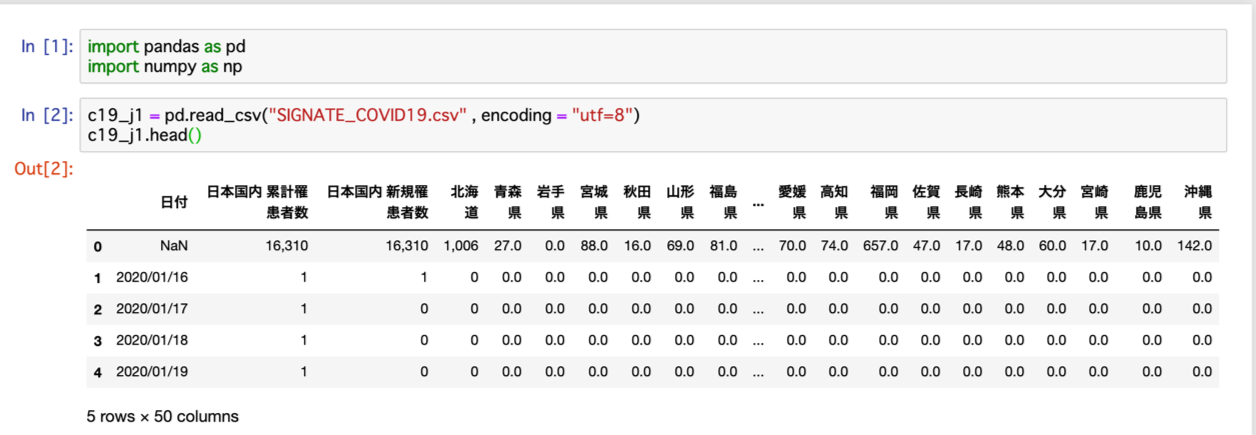
日付・日本国内累計罹患者数・日本国内新規罹患者数の3列に47都道府県の47列を足した合計50列とhead()メソッドの5行が表示されました。
このデータをさらに処理して、次回の作業を進めようと思います。

