Part1に引き続き、今回も日本版(1)のデータの前処理編です。
前回、signate_covid-19_dataset内にあるSIGNATE COVID-19 Case Datasetから罹患者統計シートをcsvデータにしてダウンロードし、それをpandasで読み込むところまでを行いました。
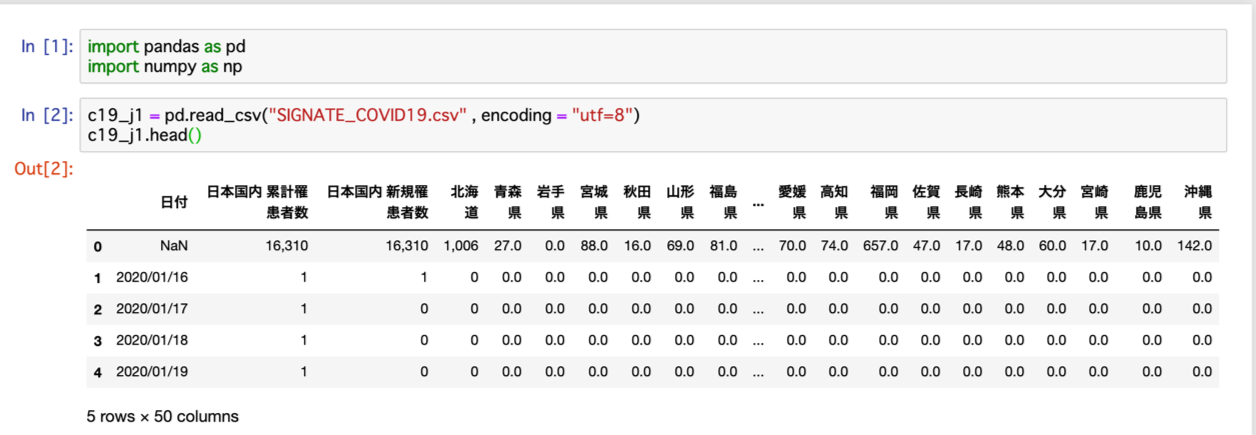
今回はそのデータをさらに処理して、今の私がPythonで分析できるようにしたいと思います。
まず、行いたいのは不要な行・列の削除。
一行目・二列目・三列目はそれぞれ合計が表示されていますが、これは後からでも追加可能なので、この段階では一旦削除しようと思います。
#1行目を削除
c19_j1 = c19_j1[1:]
#2列目・3列目の削除
del c19_j1["日本国内\n累計罹患者数"]
del c19_j1["日本国内\n新規罹患者数"]にて1行目を削除(№1列・2行目から表示)、2列目・3列目を削除削しました。
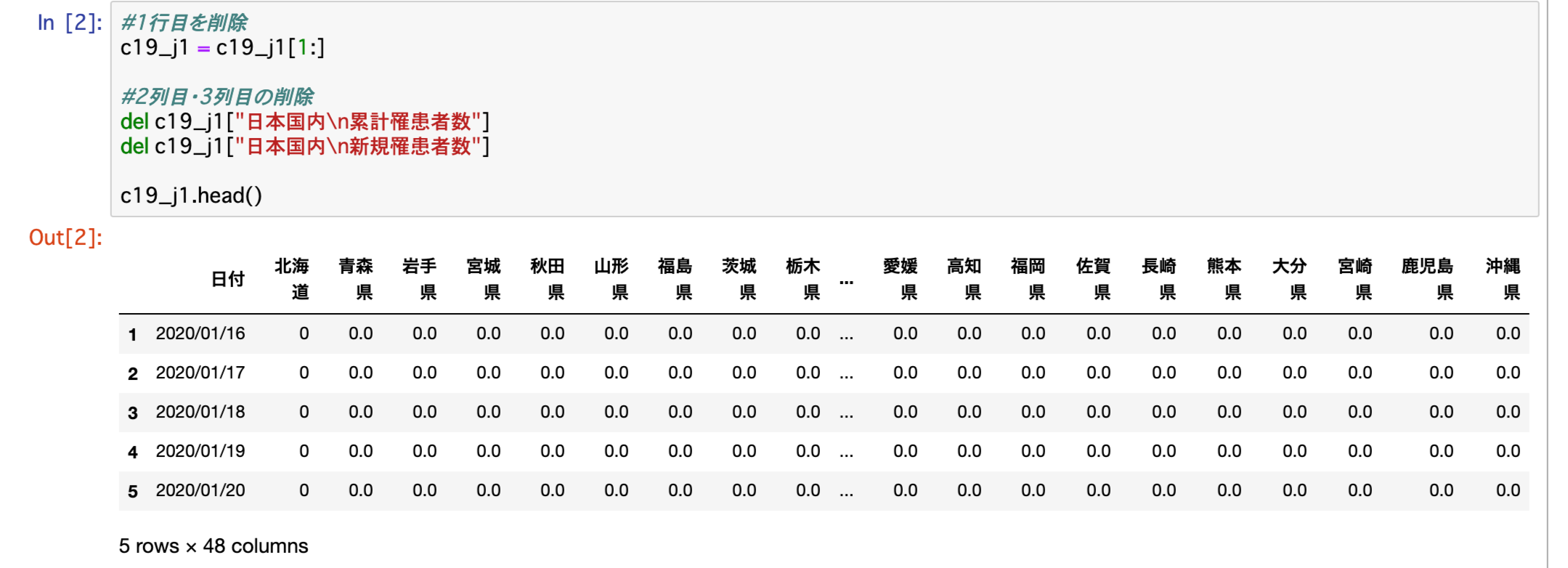
思っているデータに一歩前進です。
しかし、まだこれでは私にはPythonで処理ができません。
もう一手間手を加える必要があります。
このデータをさらに処理して、次回の作業を進めようと思います。