前回に引き続き、今回も日本版(1)のデータの前処理編です。
前回は、遅ればせながら欠損値の有無を確認。
その存在が確認できたので削除を行いました。
今回は前回で先に述べたとおり、今の私がさらに処理を進められるよう日付・罹患者数・都道府県の3列になるようにデータを形成したいと思います。
試行錯誤の結果、以下のコードを作成しました。
lo_df = []
for i in c19_j1.columns[1:] :
x = c19_j1[["日付",i]].copy()
x["Location"] = i
x = x.rename(columns={ i :"Confirmed"})
x = x.rename(columns={ "日付" :"Date"})
lo_df.append(x)
lo_df[0].head()このコードを実行してできたデータが以下となります。
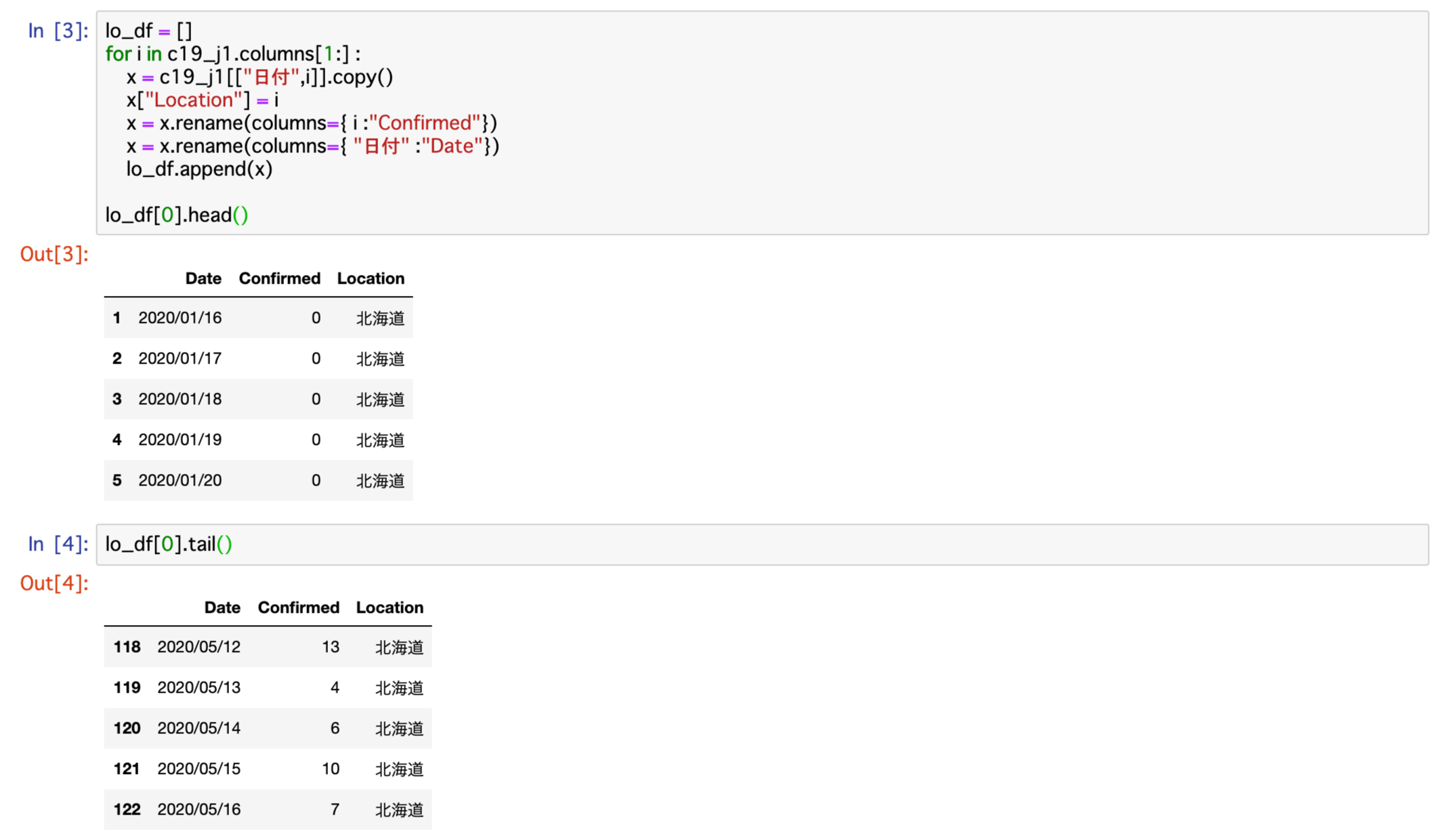
リストの中にある一つ目の内容を確認すると、北海道の2020/01/16から2020/05/16までが表示されます。
カラムの並びは北海道から始まり、沖縄で終わっていたので念の為に沖縄の内容も確認しておきます。
都道府県は47あるので、
lo_df[46].head()
lo_df[46].tail()でリストに格納された46個目を表示すると沖縄県が表示されるはずです。
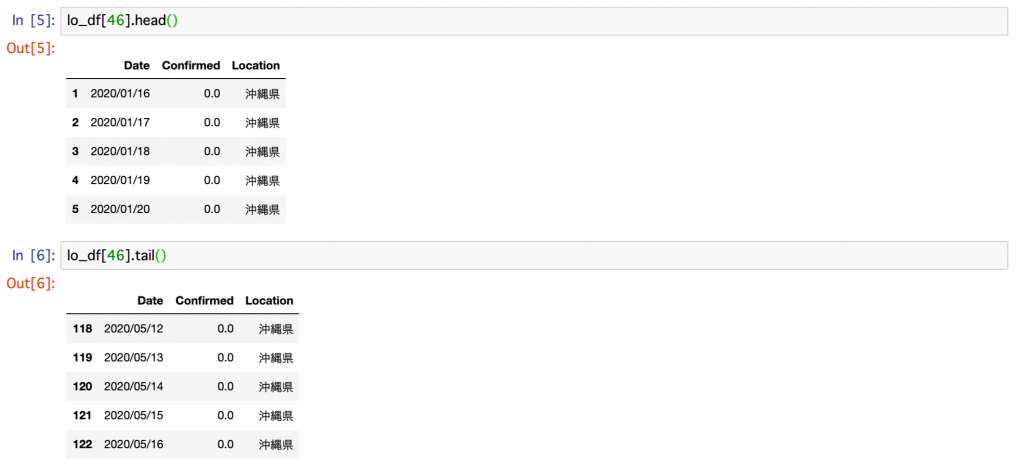
問題なく、沖縄県の2020/01/16から2020/05/16までが表示されました。
行数も北海道と同じ122行で問題はなさそうです。
かなり処理が進みました。
もう一息で、私が分析できる状態できそうです。
次に進む前に復習も兼ねて、今回のコードの内容を確認しておこうと思います。
処理の流れを分かりやすくする為にコメントを記入してみました。
#作成したデータフレームを格納する空のリストを作成
lo_df = []
#カラムの都道府県をfor分で回す
for i in c19_j1.columns[1:] :
#日付と該当する都道府県の感染者数の二列のデータを作成
x = c19_j1[["日付",i]].copy()
#列「Location」を作成し、該当する都道府県名を入力
x["Location"] = i
#2列目のカラムを都道府県名から「Confirmed」に変更
x = x.rename(columns={ i :"Confirmed"})
#1列目のカラムを日付から「Date」に変更
x = x.rename(columns={ "日付" :"Date"})
#変数xをデータフレームlo_dfに格納
lo_df.append(x)
#リストに格納されたデータフレームの確認
lo_df[0]流れとしては、カラムをfor分で回し、取り出した各都道府県でそれぞれ以下処理を行います。
まず、カラム一番目の北海道からスタート。
日付と感染者数の2列にし、新しい列Locationを追加、該当する都道府県名を記入します。
このままだと感染者数のカラム名が元の都道府県名のままなのでConfirmedに変更します。これは後でデータを結合して一つにする際に、カラムの名前を統一しておくことが必要だからでもあります。
さらに、カラム名が日付だけ日本語だと整合性が取れないので、こちらもDateに変更することにしました。
上記処理をカラム分の47回繰り返し、47都道府県分のデータプレームを格納するリストを作成しました。
このデータをさらに処理して、次回の作業を進めようと思います。