Part2に引き続きデータの前処理編となります。
前回は今後の方針として、読み込んだ元データを日付・感染者数・回復者数・死亡者数・PCR検査数の5列、2020/02/05〜2020/06/08までの120行の持つデータに整形することを決定しました。
今回は現在22あるカラムから必要なカラムだけを選択し、さらに名前も私の希望するそれに変更してみようと思います。
まずはカラムの選択から始めます。
復習を兼ねて元データの内容を確認しておきます。
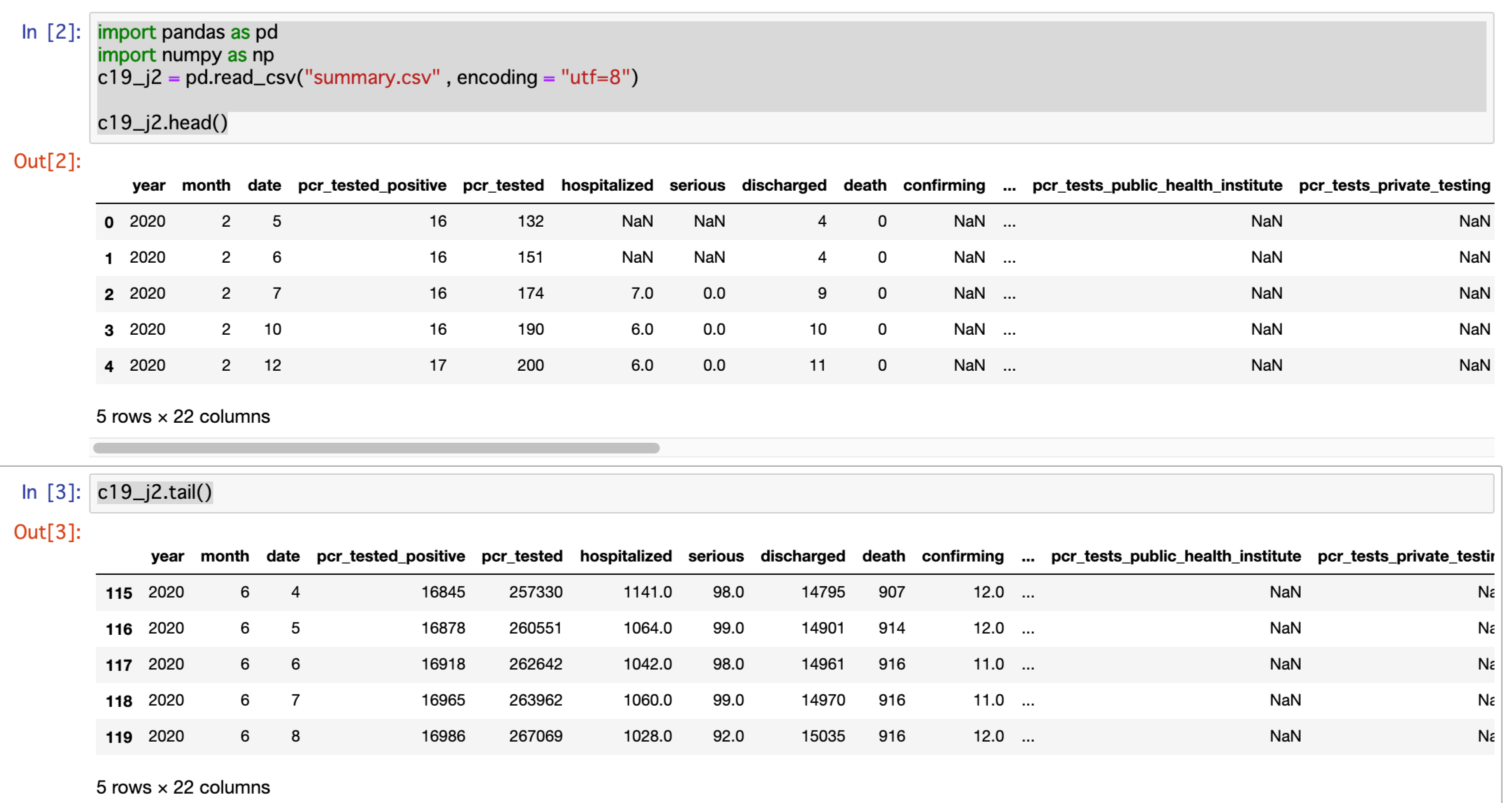


この中から必要なカラムyear・month・date・pcr_tested_positive・discharged・death ・pcr_testedのみを選択します。
c19_j2 = c19_j2[["year","month","date","pcr_tested_positive","discharged"
,"death","pcr_tested"]]
c19_j2.head()
c19_j2.tail()上記コードを実行し、表示された結果が以下となります。
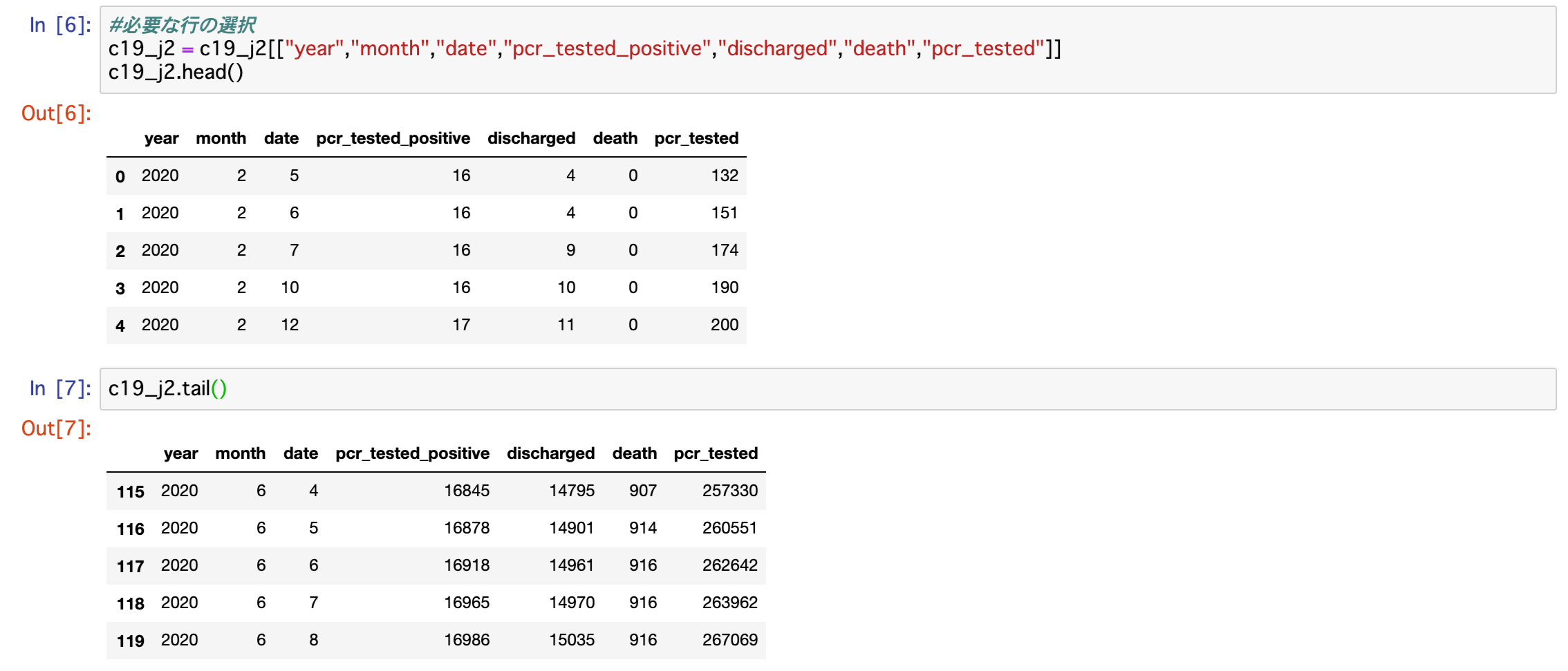
無事、指定した列のみが表示されました。
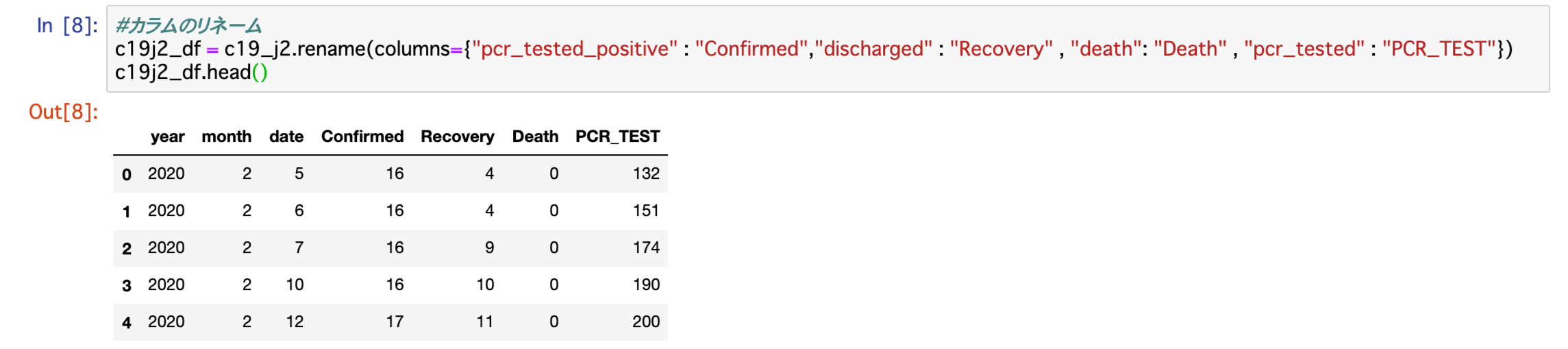
さらにカラムの名前を変更します。
PCR検査陽性のpcr_tested_positiveを感染者のConfirmed、退院のdischargedを回復者のRecovery、deathはDeath、pcr_testedはPCR_TESTにそれぞれリネームを行います。
c19j2_df = c19_j2.rename(columns={"pcr_tested_positive" : "Confirmed",
"discharged" : "Recovery" , "death": "Death" , "pcr_tested" : "PCR_TEST"})
c19j2_df.head()上記コードを実行し、表示された結果が以下となります。
year・month・dateに関しては、年月日にまとめた新しい列Dateを作成した後、最終的には削除する予定です。
次回は個別になっているyear・month・dateを年月日にまとめ、新しい列Dateに格納しようと思います。