今回は完成したプログラムc19j2_df_ver1.0が最新のデータに対して問題なく動作するかを確認しようと思います。
日本版(2)は東洋経済オンライン編集部の荻原和樹氏がGitHubで公開しているデータを使わせていただきます。
上記にアクセスしてデータをダウンロード。
dataフォルダー内にあるsummary.csvの内容の確認を行います。
本稿執筆の2020/06/17時点で2020/02/05から2020/06/16までのデータが存在することが確認できます。
実際にプログラムc19j2_df_ver1.0を走らせて確認し、先頭が2020/02/05で、末尾が2020/06/16になっていれば問題ないと判断できます。
以下が完成したプログラムとなります。
import pandas as pd
import numpy as np
c19_j2 = pd.read_csv("summary.csv" , encoding = "utf=8")
c19_j2.head()
c19_j2.tail()
c19_j2.columns
c19_j2.info()
#必要な行の選択
c19_j2 = c19_j2[["year","month","date","pcr_tested_positive","discharged","death","pcr_tested"]]
c19_j2.head()
c19_j2.tail()
#カラムのリネーム
c19j2_df = c19_j2.rename(columns={"pcr_tested_positive" : "Confirmed","discharged" : "Recovery" , "death": "Death" , "pcr_tested" : "PCR_TEST"})
c19j2_df.head()
# 年・月・日と、それらをまとめた年月日を、格納する空のリストを作成
ymd_l = []
y_l = []
m_l = []
d_l = []
# 年・月・日をそれぞれリストに格納する処理
for y in c19_j2["year"]:
y = str(y)
y_l.append(y)
for m in c19_j2["month"]:
# 文字列にキャスト
m = str(m)
# 数字が一桁だった場合、先頭に0を加える処理
if len(m) == 1:
m = "0" + m
m_l.append(m)
else:
m_l.append(m)
for d in c19_j2["date"]:
# 文字列にキャスト
d = str(d)
# 数字が一桁だった場合、先頭に0を加える処理
if len(d) == 1:
d = "0" + d
d_l.append(d)
else:
d_l.append(d)
# 年・月・日の各リストからそれぞれを取り出し、加算して年月日に整形、リストに格納
nums = len(m_l)
for num in range(nums):
ymd = y_l[num] + m_l[num] + d_l[num]
# print(len(ymd))
# print(ymd)
ymd_l.append(ymd)
# 年月日リストをデータフレームに変換し、データフレームc19_j2にDate行として追加
c19_j2["Date"] = pd.DataFrame(ymd_l)
c19_j2 .head()
#カラムの並び替え
c19_j2 = c19_j2[["year","month","date","Date","pcr_tested_positive","discharged","death","pcr_tested"]]
c19_j2.head()
#カラムのリネーム
c19j2_df = c19_j2.rename(columns={"pcr_tested_positive" : "Confirmed","discharged" : "Recovery" , "death": "Death" , "pcr_tested" : "PCR_TEST"})
c19j2_df.head(10)
c19j2_df.tail(10)
#不要列の削除
del c19j2_df["year"]
del c19j2_df["month"]
del c19j2_df["date"]
c19j2_df.head()
c19j2_df.tail()
#欠損値の確認
c19j2_df.isnull().sum()
#データ内容の確認
c19j2_df.info()
#csvファイルに書き込み
c19j2_df.to_csv("c19j2_df_20200616.csv", index = False, encoding="utf-8")出来上がったデータを読み込んで確認します
c19j1_df = pd.read_csv("c19j2_df_20200616.csv" , encoding = "utf=8")
c19j1_df.head()
c19j1_df.tail()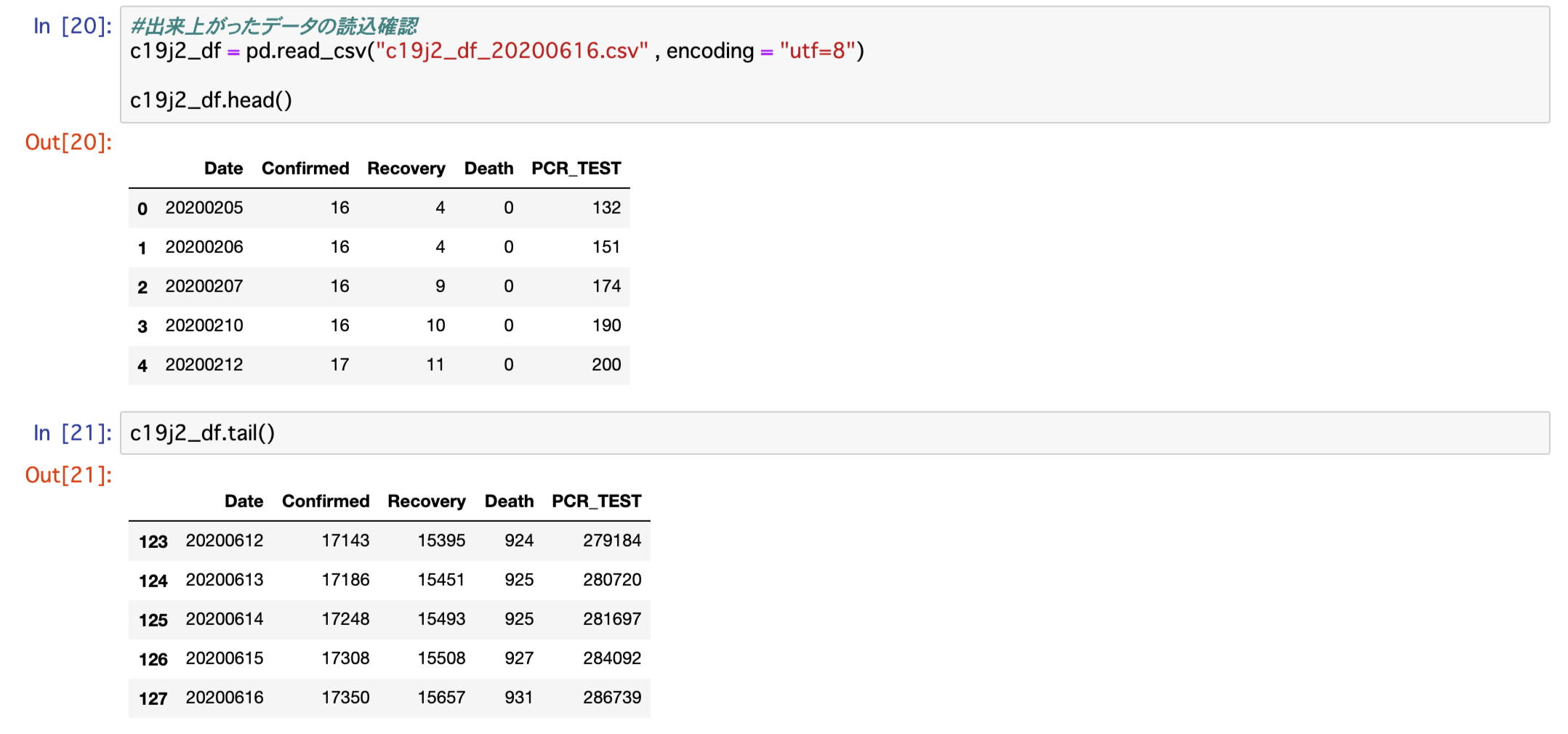
次いで欠損値の確認を行います。
c19j2_df.isnull().sum()
欠損値のないことが確認されました。
さらにデータの内容を確認して置きます。
128行のデータになっていれば問題なしということです
c19j2_df.info()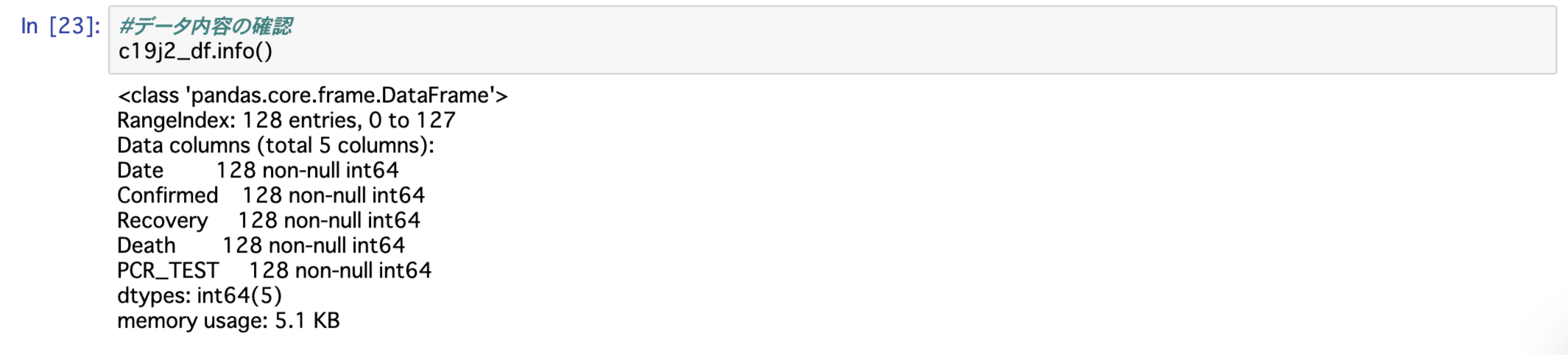
表示された結果、問題なく128行のデータであることが確認できました。
これで準備が完了しました。
次回は、いよいよ可視化を行い分析に取りかかろうと思います。