前回に引き続き世界版のデータの前処理を続けます。
まずは前回までの作業で出来上がったデータの内容を確認します。
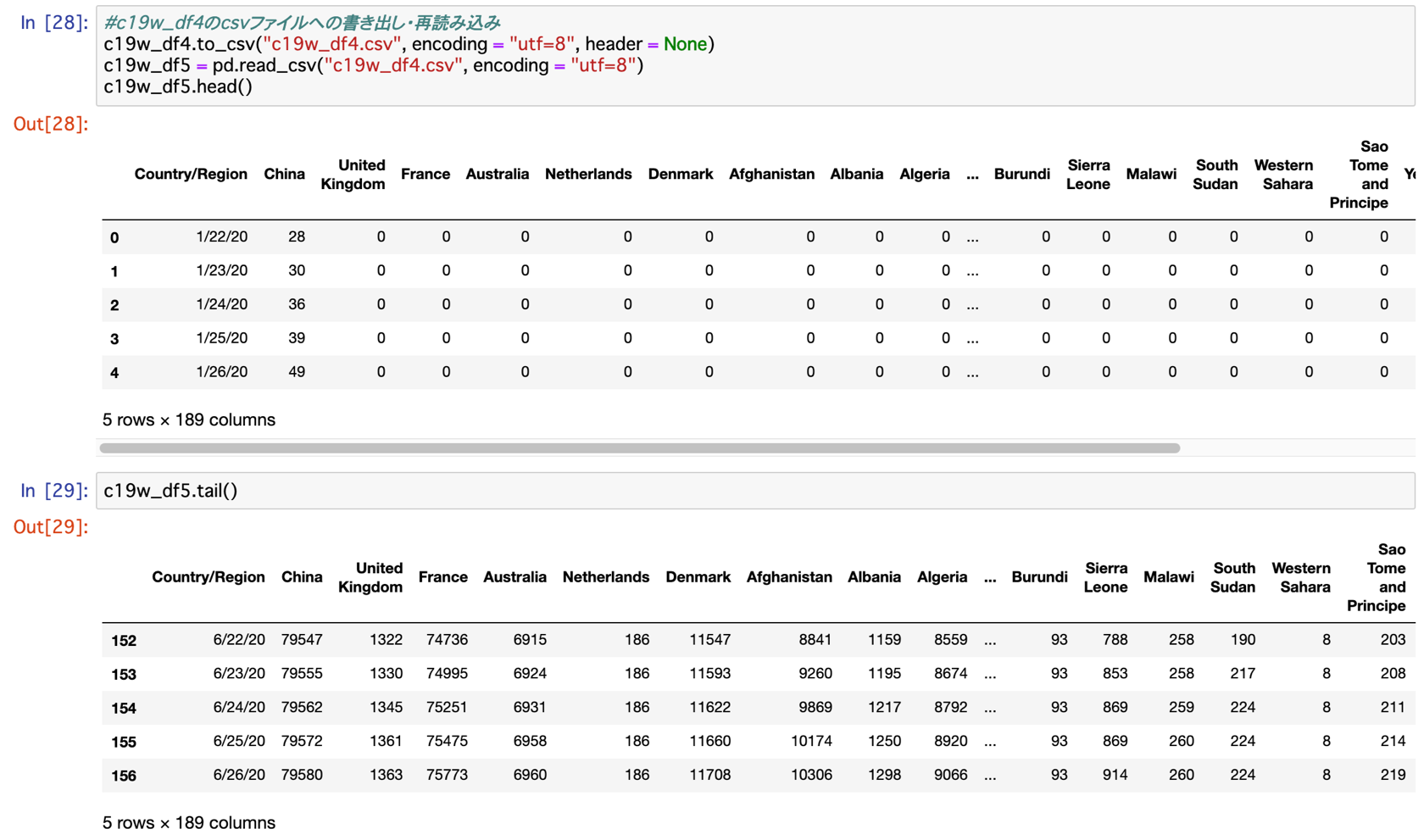
カラムに国名・インデックスに日付。
各行にはそれぞれの国の累計の数字が入っています。
これは日本版(1)の元データと構成と同じです。
日本版(1)ではカラムが都道府県・インデックスに日付でした。
つまり、同じ方法で処理を進めることができるということです。
その為、最終的に日付・国名・状況(今回の場合はRecovered)の3列のデータになるようにデータの整形を行います。
日本版(1)で使用したデータを手直しした以下のコードを実行します。
#作成したデータフレームを格納する空のリストを作成
lo_df = []
#カラムの国名をfor分で回す
for i in c19w_df5.columns[1:] :
#日付と該当する国の感染者数の二列のデータを作成
x = c19w_df5[["Country/Region",i]].copy()
#カラム「Countryを作成し、該当する都道府県名を入力
x["Country"] = i
#二列目の国名iを「Confirmed」に変更
x = x.rename(columns={ i :"Recovered"})
#1列目のカラムを「Country/Region」から「Date」に変更
x = x.rename(columns={ "Country/Region" :"Date"})
#変数xをデータフレームlo_dfに格納
lo_df.append(x)
#最初の国のデータ確認
X = lo_df[0]
X.head()
X.tail()
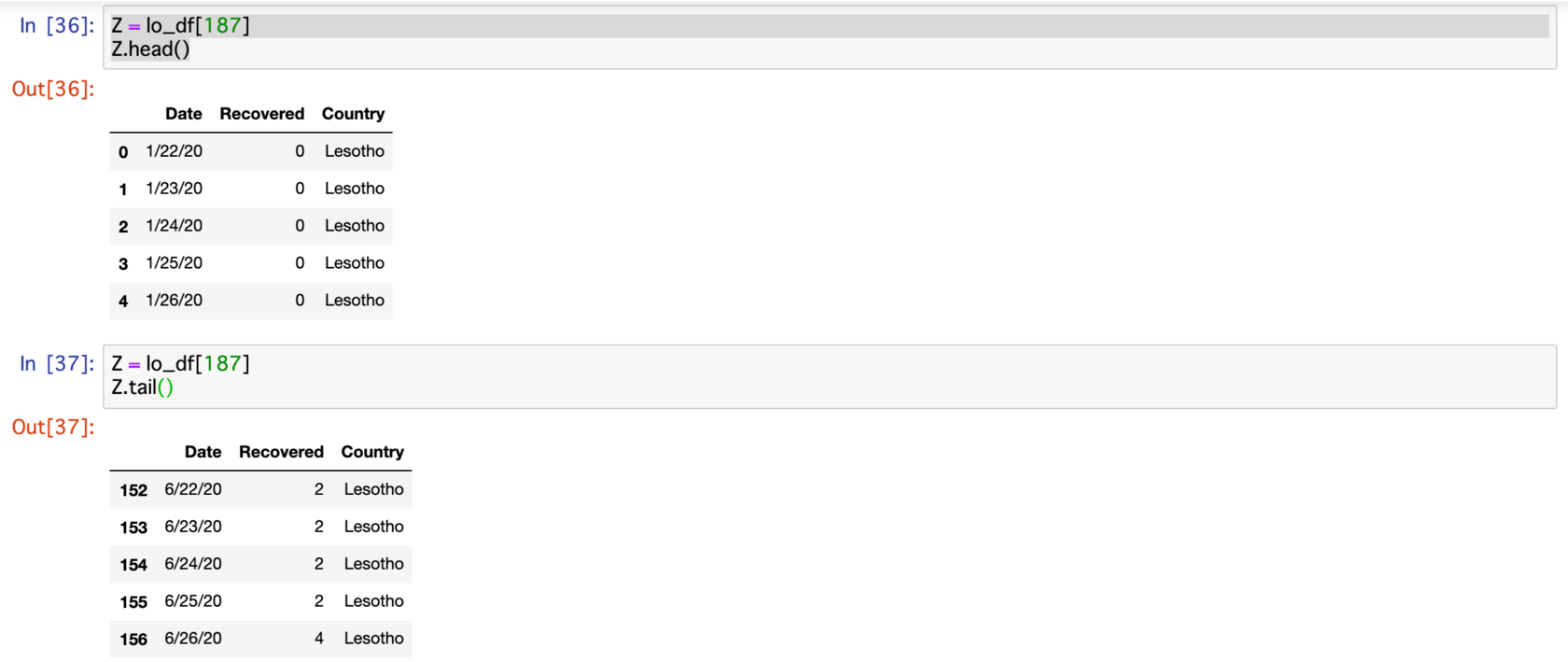
#最後の国のデータ確認
Z = lo_df[187]
Z.head()
Z.tail()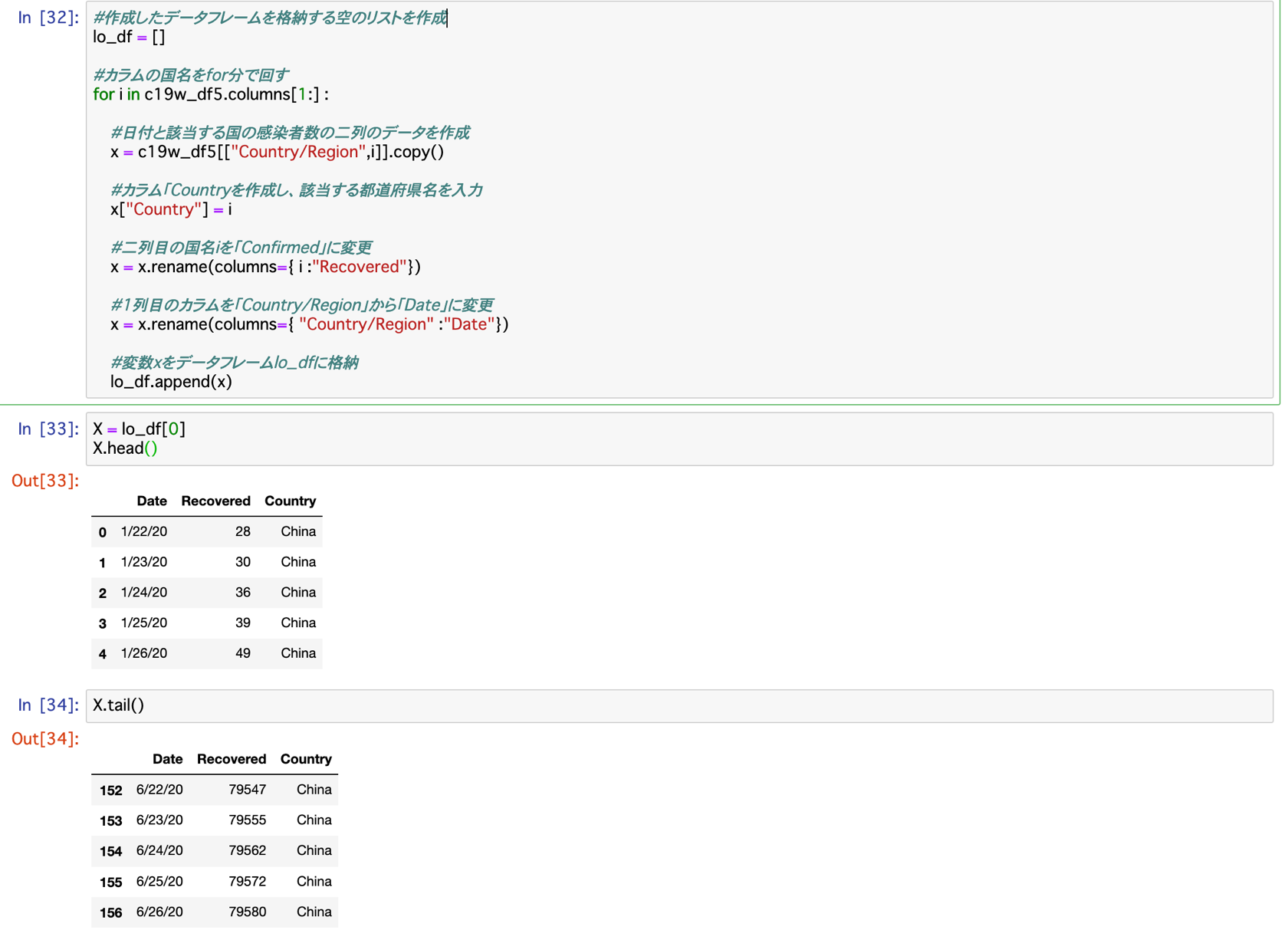
かいつまんで処理の内容を説明すると
データセットc19w_df5を整形し、188カ国分のDate・Recovered・Countryの3列のデータセットを作成しリストに格納。
さらに、それらが正しくリストに格納されているかを確認しています。
1国目のChinaの1/22〜6/26、188国目のLesothoの1/22〜6/26を抽出して確認を行いました。
問題はなさそうです。
さらに日付の整形を行います。
現在は1/22/20と月/日/年の並びになっています。
さらに年は下二桁のみ、月・日は数字が一桁の場合は一桁表示になっています。
これを年は四桁、月・日は一桁の場合に0を追加して必ず二桁表示になるようにし、さらに/を削除、20200122と年月日の並びになるように変更を行います。
処理は以下のコードで行います。
こちらも日本版(1)の改良版となります。
#年月日を格納する空のリストを作成
ymd_l = []
y_l = []
m_l = []
d_l = []
for i in range(len(X["Date"])) :
y = X["Date"][i].split('/')[2]
y = "20" + y
y_l.append(y)
for i in range(len(X["Date"])) :
m = X["Date"][i].split('/')[0]
if len(m) == 1:
m = "0" + m
m_l.append(m)
else:
m_l.append(m)
for i in range(len(X["Date"])) :
d = X["Date"][i].split('/')[1]
if len(d) == 1:
d = "0" + d
d_l.append(d)
else:
d_l.append(d)
nums = len(m_l)
for num in range(nums):
ymd = y_l[num] + m_l[num] + d_l[num]
#print(len(ymd))
#print(ymd)
ymd_l.append(ymd)
先程と同様にリストの最初と最後を確認します。
最初が20200122、最後が20200626になっていれば問題なく変換・格納されていることになります。
len(ymd_l)
ymd_l[0]
ymd_l[156]
リストに格納されている日付は全部で157。
そして、0番目と156番目を表示すると20200122・20200626と予定通りの日付が表示されました。
これで日付の整形が終わりです。
後は現在バラバラの188国分のデータセットを1つに結合し、先程作成した日付を新たな行として追加、カラムの並び替え・リネームを行えばRecoveredのデータセットの完成ですが、まだもう少し時間が必要なので、今回はここまでにしておこうと思います。