今回から、いよいよ分析に取りかかります。
本コンペの目標は「予測精度の高い貸し倒れ予測モデルの作成にチャレンジしてみましょう」というもの。
データを読み込み基礎分析を行ったところ、以下の内容が表示されました。
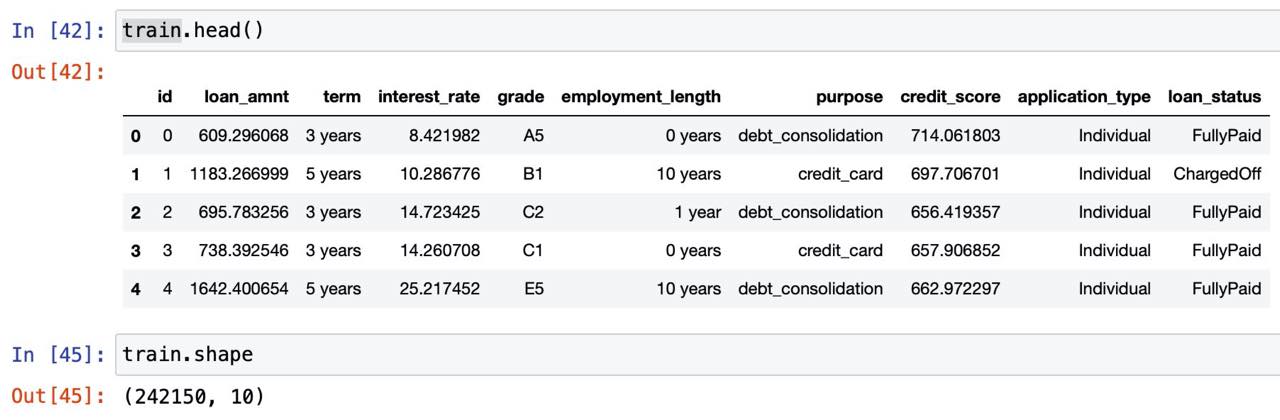
242150行・10列のデータ。
そして、今回目指すのはloan_statusがChargedOffになる場合を予測するモデルの構築になります。
さらに基礎分析を進めます。
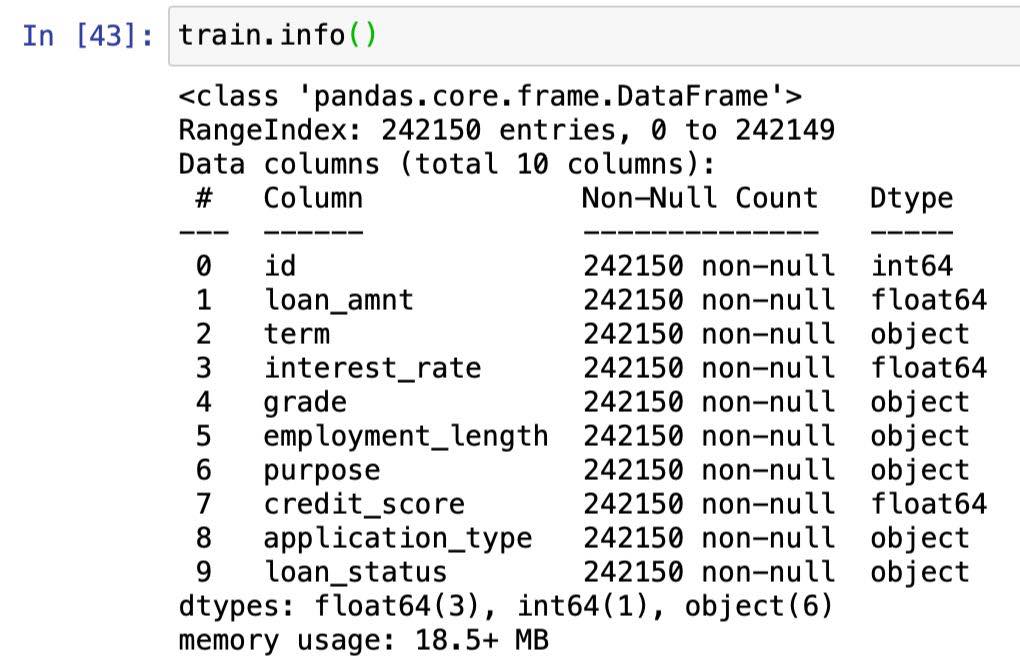
各カラムの型を確認するとloan_amnt・interest_rate・credit_scoreの3列が量的データ、その他7列は質的データということです。
機械学習の説明変数に使えるのは量的データのloan_amnt・interest_rate・credit_scoreの3つになり、こちらを使用することにします。
目的変数はloan_statusになりますが、現在は質的データとなっています。
その為、量的データに変換する必要があります。
今回は、ChargedOffを1、FullyPaidを0と量的データ変換したloan_status2という新しい列を作成することにします。
欠損値の確認を行ったところいずれも0だったので、データの前処理を始めることにします。
行ったのは質的データであるloan_statusを0と1の量的データに変換した新しいカラムloan_status2の作成。
さらに説明変数としてloan_amnt・interest_rate・credit_scoreの3列のカラムを、目的変数として先程作成したloan_status2を用意します。
上記をtrain_test_split関数を使って学習用データ・評価用データに分割し、これで前処理は終了となります。
いよいよモデルの作成です。
今回使用する機械学習アルゴリズムはロジスティック回帰(LogisticRegression)。
予測結果を投稿する前に、f1_scoreを使ってモデルの評価を行っておきます。
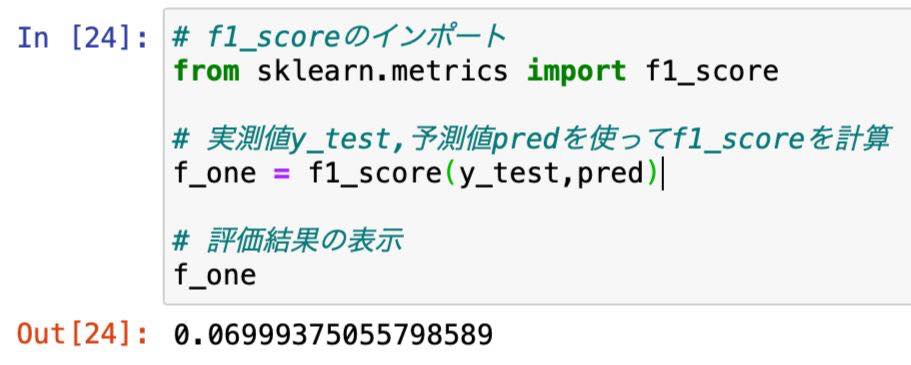
表示された結果を見る限り悪い、というか、とても悪いと評価するしかありません。
f1_scoreは1に近いほど良いとされる評価指標。
小数点第二位のスコアでは話しにならないと思われます。
しかし、これも結果。
とりあえず投稿してみたいと思います。
結果は案の上のランキン外。
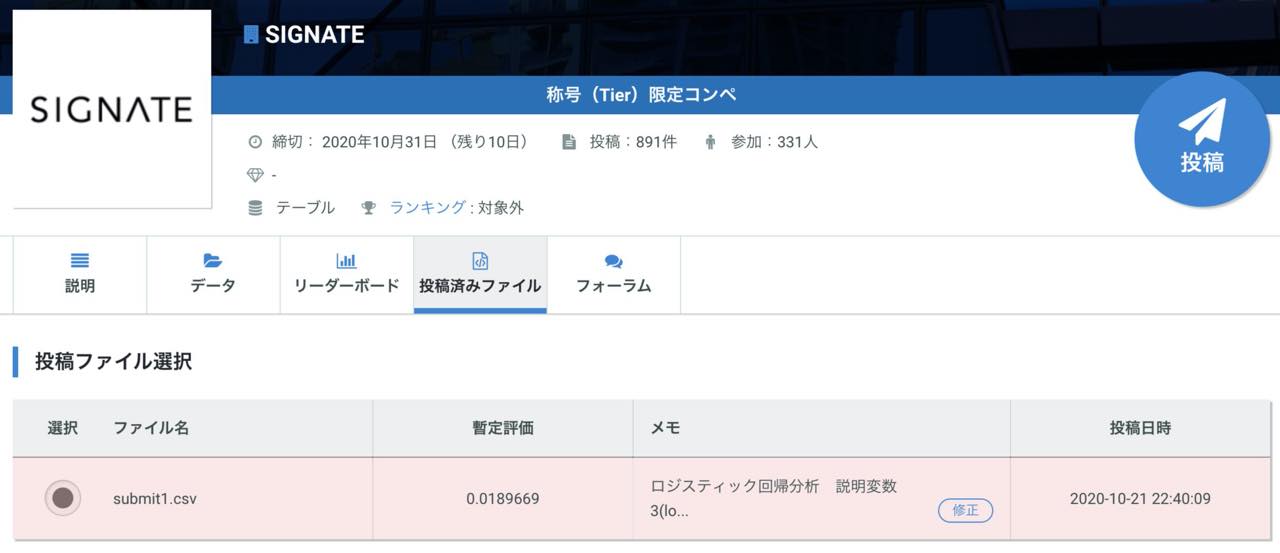
ランキングボードで順位を確認するまでもありませんでした。
まあ、用意されたデータをそのまま使用して作成した単純なモデルが高評価を出せるはずもありません。
当然の結果だと思います。
実際のところ、今の私の知識・経験でそうできることは多くありません。
しかし、残り10日間でどれだけ先に進めるか、せいぜいあがいてみたいと思います。