過去二回投稿を行いましたが、結果は178人中168位という惨憺たる結果となりました。
すでにSIGNATEの有料オンライン講座に申し込みしあらためて機械学習の勉強を開始しましたが、本コンペティションに関しては、これまでの知識・経験を使って他にも試してみたいことがあります。
その為、ランキング云々以前に、今の自分が機械学習で何が出来るのか、どこまでできるのかを残り10日間で試してみたいと思います。
とはいえ、あまり引き出しがないのも事実。
できそうな事と言えば、機械学習アルゴリズムの変更くらいです。
これまで二回の投稿は機械学習アルゴリズムはロジスティック回帰(LogisticRegression)を用いましたが、今回はこれを別のものに変えて見ようと思います。
実際、アルゴリズムの変更で大きく予測精度が変わることがあるようです。
今回使用する機械学習アルゴリズムは決定木(Decision Tree)。
以前オンライン学習サイトUdemyで受講した講座『【ゼロから始めるデータ分析】 ビジネスケースで学ぶPythonデータサイエンス入門』で決定木が使われていたので、こちらを本コンペティションに応用してみたいと思います。
というか、上記講座はSENATE公式の講座だったようです。
説明変数の多寡で予測結果に影響するかどうかも確認したいので、まずはloan_amnt・interest_rate・credit_scoreの3カラムで。
次に、term・grade・employment_length・purpose・application_typeの5カラムを追加した8カラムの順番で行おうと思います。
使用する機械学習アルゴリズムがロジスティック回帰(LogisticRegression)か決定木(Decision Tree)か以外、手順自体は変わりません。
学習用データ・評価用データに分割し、予測を行います。
f1_scoreを使って予測結果の評価を行うと以下の結果が表示されました。

説明変数8カラムで出た0.13453595212003708は上回るものの、劇的に良くはなりませんでした。
続いて8カラムでの予測結果の評価を行います。
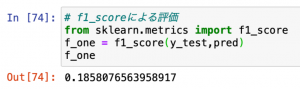
結果は3カラムの時とまったく同じでした。
決定木とはこういうものなのでしょうか?
ともあれ、これで投稿してみることにします。
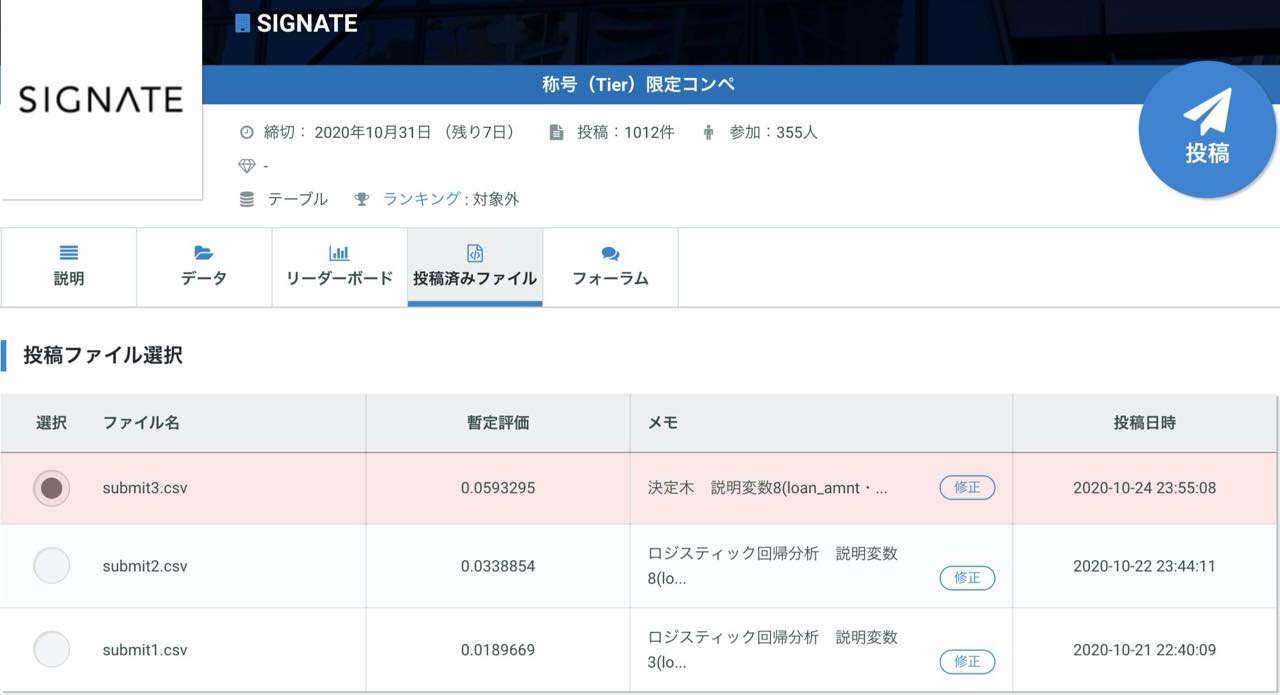
結果は、
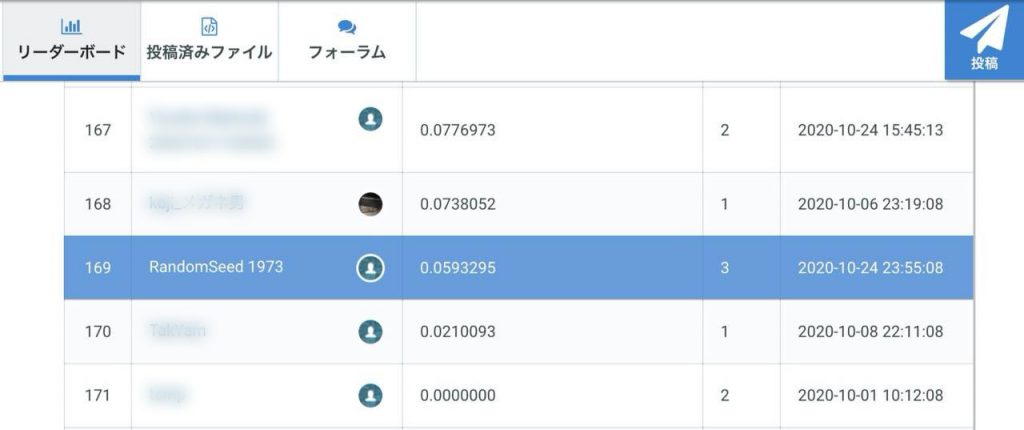
結果は179人中169位。
参加人数の下から10位。
参加人数が1人増えて、その分下がった格好です。
しかし、先述のとおり、本コンペティションに関しては、ランキング云々以前に、今の自分が機械学習で何が出来るのか、どこまでできるのかを試すつもりです。