前回、学習用データと評価データにデータを分割する前に、loan_statusのFullyPaidとChargedOffの数を調整することで、予測評価の大幅な改善が見られました。
これに気を良くし、いくつかの機械学習アルゴリズムを変更して予測精度の改善を試みたのですが、結果は良くて前回と同等、それ以上の成果に結びつくことはありませんでした。
その為、もう一度特徴量・説明変数に立ち戻ることにしました。
現在の説明変数ではこれ以上の予測精度向上は難しいと判断した為です。
ひとつは量的データの桁数。
現在は小数点以下の数字が第6位までと非常に多いですが、この数を調整してみることにします。
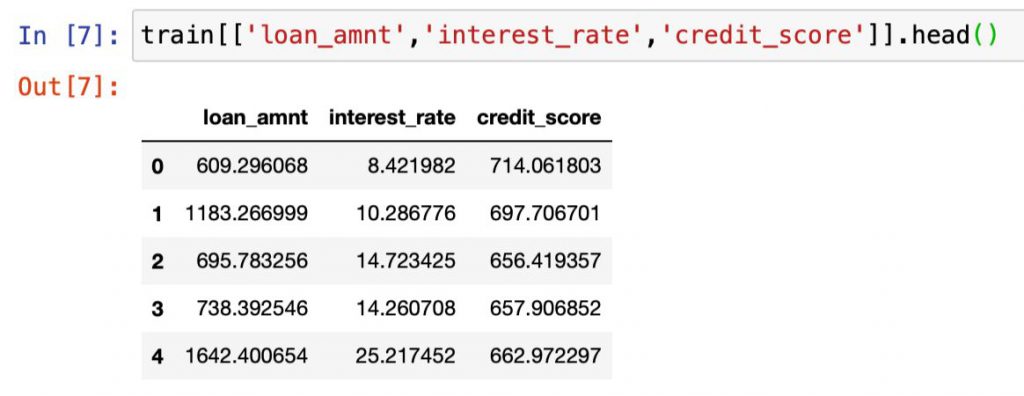
小数点以下の数字を切り捨ててみたり、逆に10や100の位に切り上げてみたりと色々と試した末に投稿したところ、結果は次の通りとなりました。
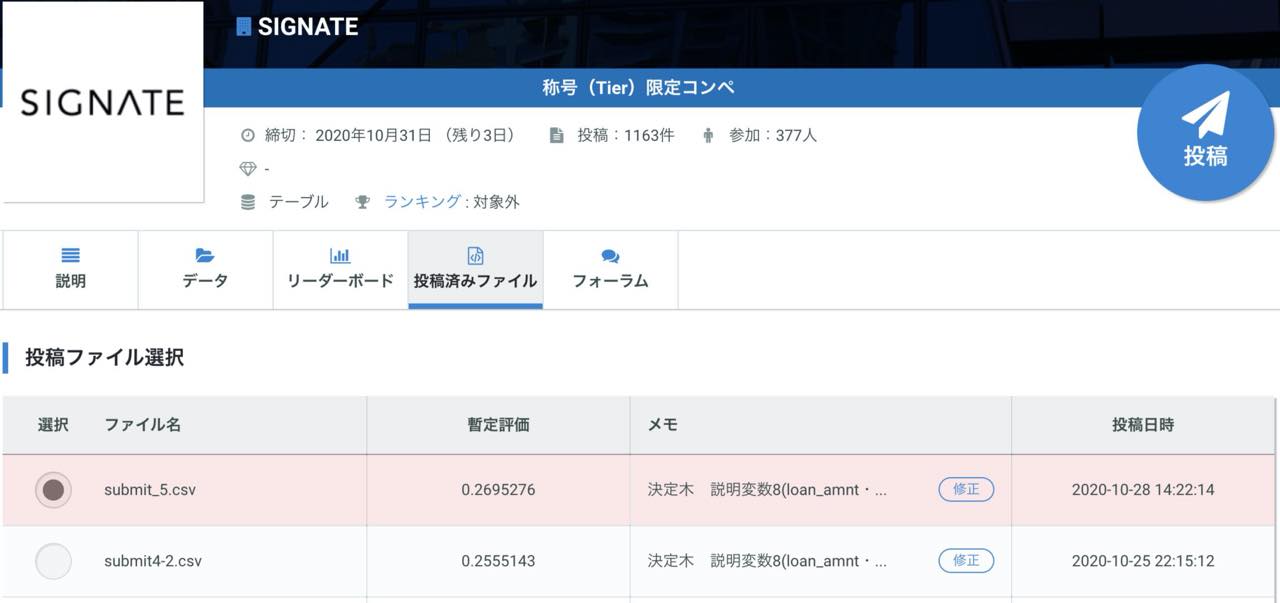
0.2555143から0.2695276へと僅かならが数値がアップしました。
しかし、リーダーボードで順位を確認すると、
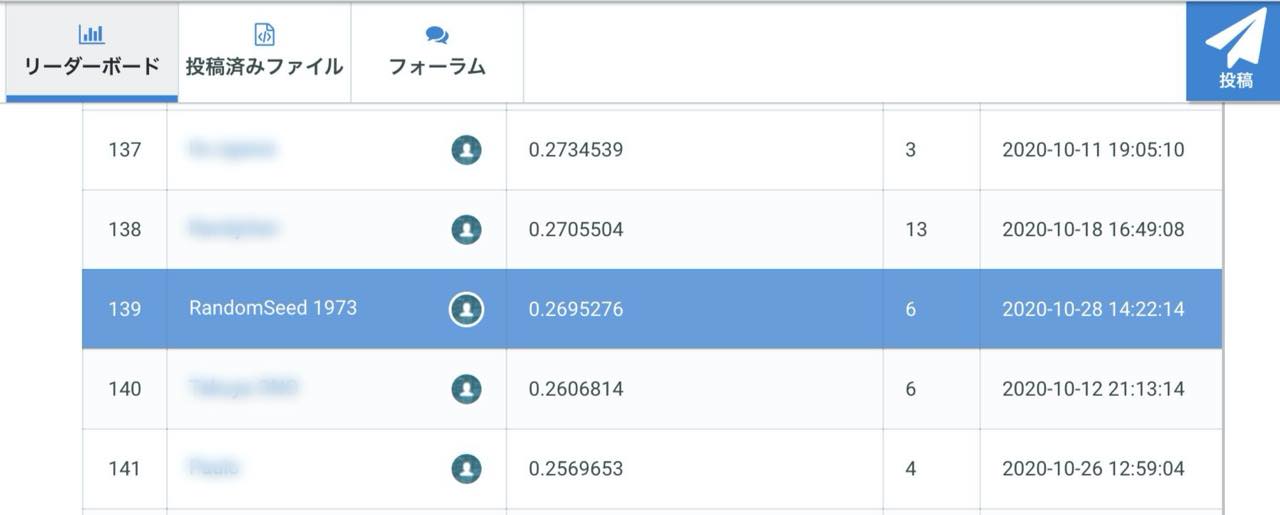
前回の128位から10位ランクダウンしての139位でした。
残念な結果ですが、これが現実なので仕方がありません。
残り4日。
まだアイデアはあるので、最後まであがいてみようと思います。