今回、行いたいのはPythonによる機械学習。
重回帰分析を使った日本のCOVID-19の感染者数・死亡者数の未来予測です。
データは【PythonでCIVID-19分析】日本版(2)で個人的に作成・使用しているデータを使用。
まずは感染者数の予測に取り組むことから始めようと思います。
最初に日本版(2)のデータ内容の確認から始めます。
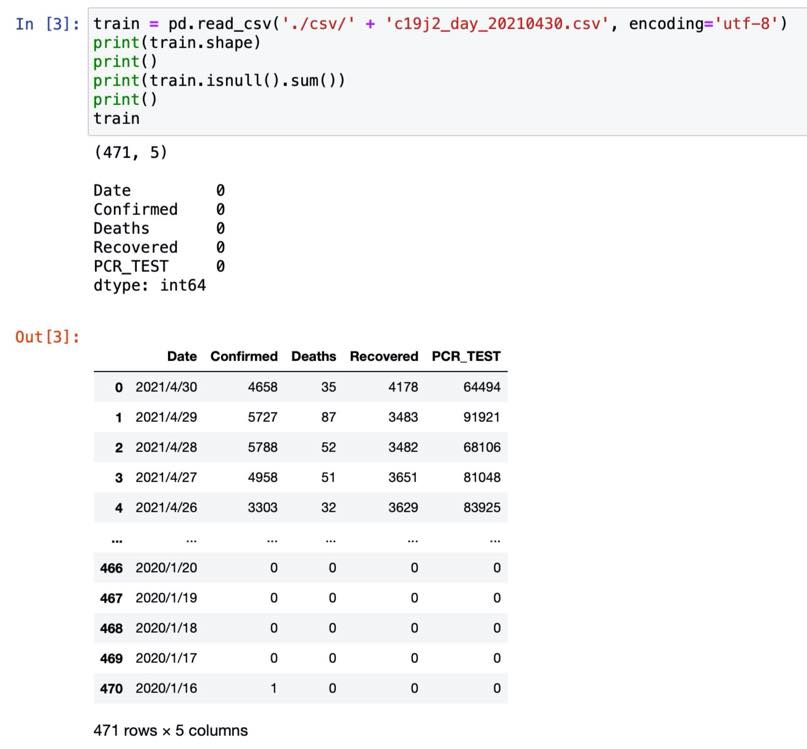
日本版(2)のデータは厚生労働省オープンデータから取得し、日付・感染者数・死亡者数・回復者数・PCRテスト数の5列。
今回は5/1時点で最新の2020/1/18〜2021/4/30迄のデータ471行を使用します。
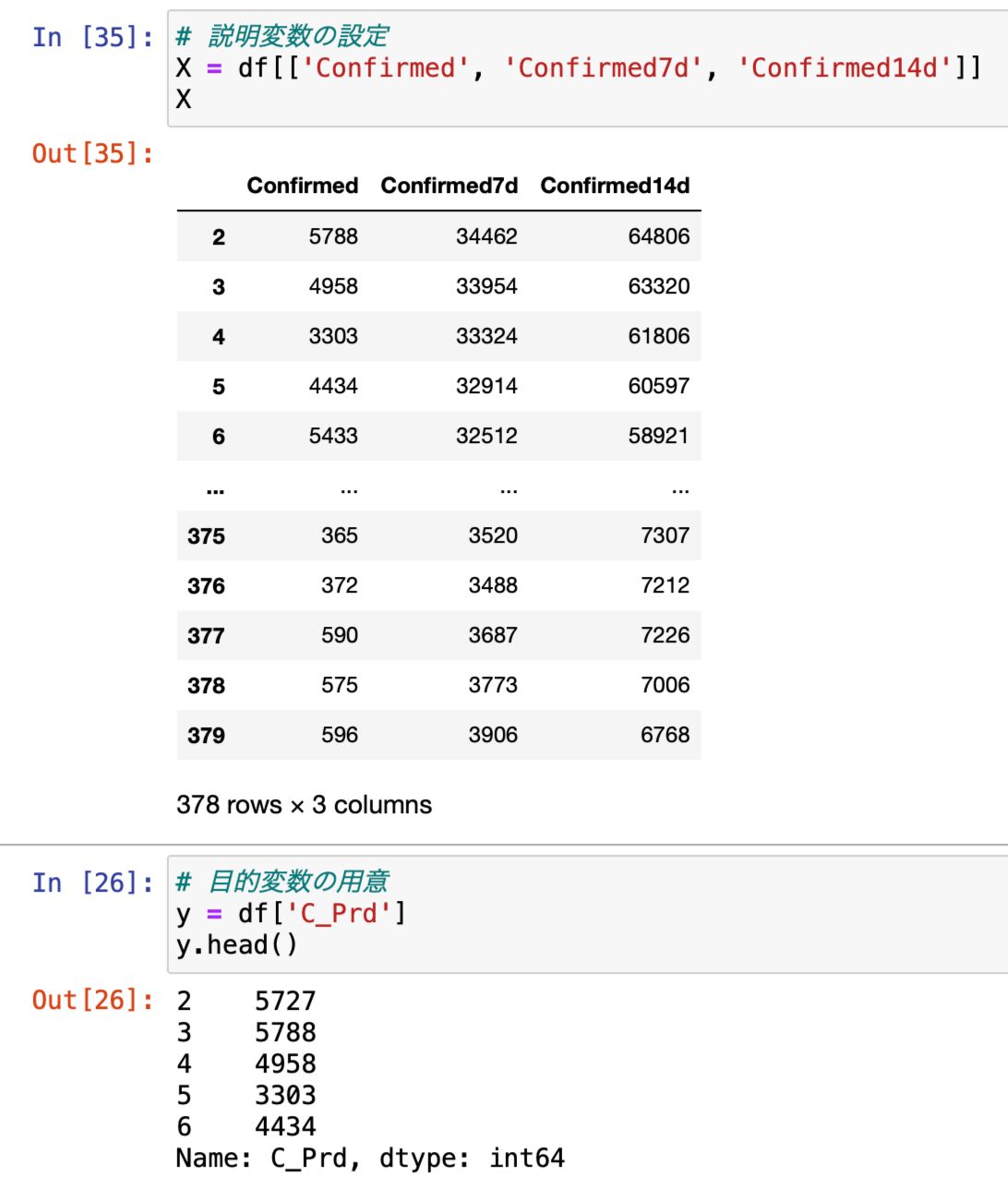
今回は感染者数の予測なので感染者数のみを説明変数に使用しようと思います。
それだけでは少ないと思うので、先の日毎の数字に加え、7日毎(当日+過去6日)、7日毎、14日毎(当日+過去13日)の加えて、その3つを説明変数にすることにしました。
7日毎(当日+過去6日)、7日毎、14日毎(当日+過去13日)はそれぞれ日毎データを加工して作成。
目的変数は当日の翌日の数字を使用します。
4/29なら4/30、1/1なら1/2といった具合です。
よって、使用する日付は4/30から一日引いた4/29迄となります。
スタートの2020/4/16は感染者数が本格化した日付を選んだだけで深い根拠があるわけではありません。
この辺りは必要に応じて今後再設定する必要がありそうです。
以下が今回用意した目的変数と説明変数となります。
上記データを使用して、重回帰分析を用い機械学習を行った結果は以下の通りです。
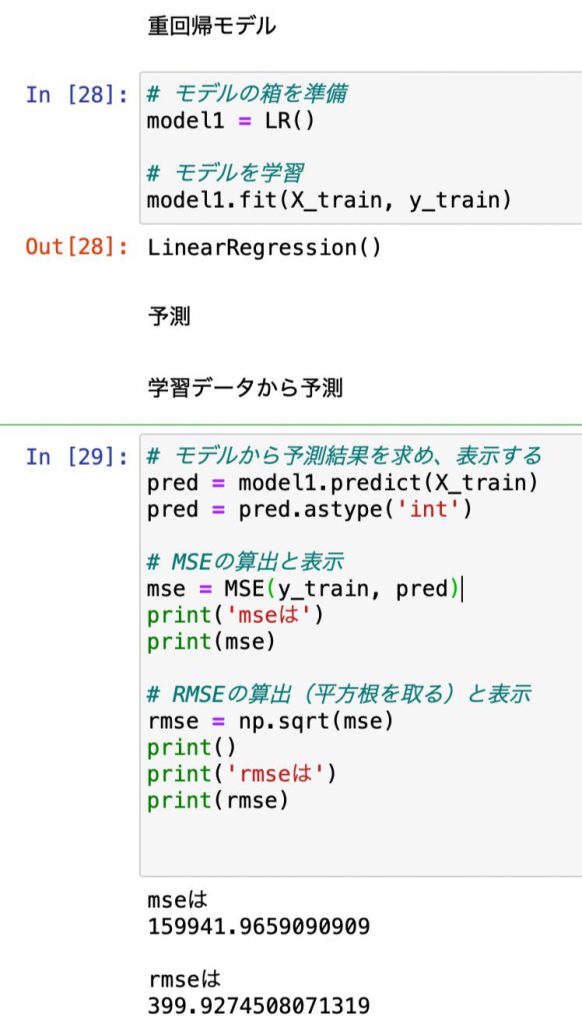
評価関数はMSE・RMSEを使用しました。
結果は
MSE:159941
RMSE:399
MSEとは平均二乗誤差(MSE:Mean Squared Error)。
各データに対して「正解値と予測値の差(=誤差)」を二乗した値を計算し、その総和をデータ数で割った値(=平均値)を表します。
最も一般的な損失関数でもあるため、そのまま評価関数としても用いられます。
RMSEとは平均二乗誤差の平方根(RMSE:Root Mean Squared Error)。
RMSEは、平均二乗誤差(MSE)の単位問題を回避するため*2の評価関数として利用します。
どちらも予測精度は0に近いほど高い。
つまり、今回の学習結果は、お世辞にもよろしくありません。
しかし、元々分不相応に難しい課題に挑んでいるので、この結果は当然でもあります。
これからが本番。
MSE・RMSEの数値を0に近付けられるかが、これからが今回の本当の挑戦です。