Pythonによる機械学習でCIVID-19の感染者数を予測する試みも今回で三回目。
今回も重回帰モデルを用いて、当日の数字から翌日の数字の予測を行います。
前回の予測の結果、は長い期間での数字の方が、短い期間での数字より、予測精度の改善に寄与することが分かりました。
その為、今回は既に用いている14日毎(当日+直近過去13日)よりも長い期間を特徴量として用いてみようと思います。
まずは14日毎(当日+直近過去29日)から試してみようと思います。
日毎・14日毎・30日毎を特徴量に予測した結果が以下となります。
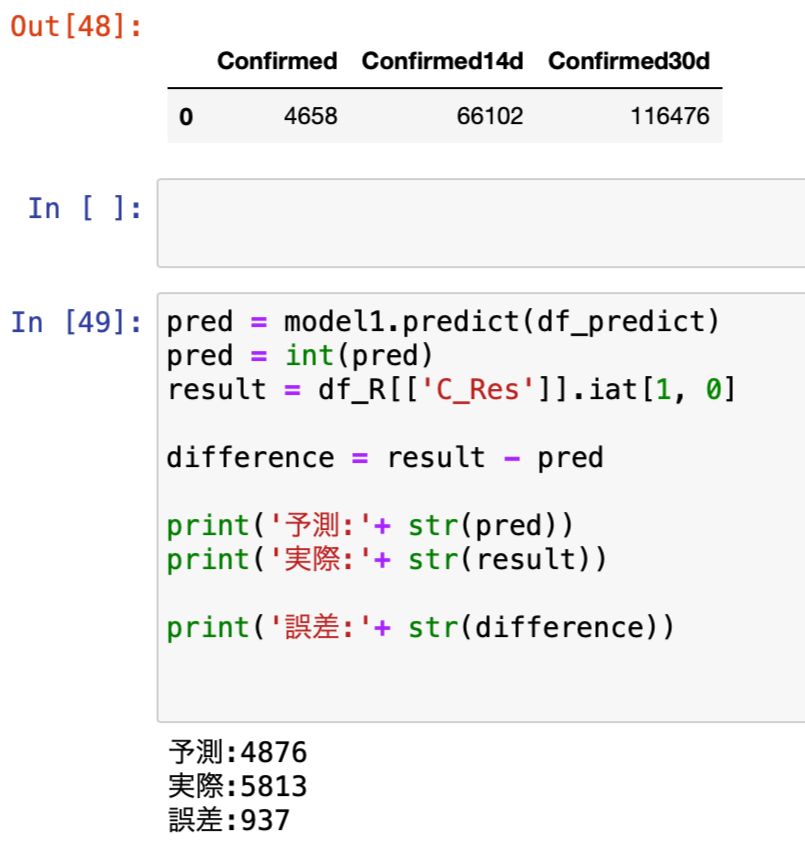
予測と実際の誤差は937人。
Ver1.00の1,151人を行き成り上回る好結果となりました。
さらに特徴量を追加してみます。
今度は日毎・14日毎・30日毎に60日毎を特徴量に加えてみます。
結果は以下のとおりです。
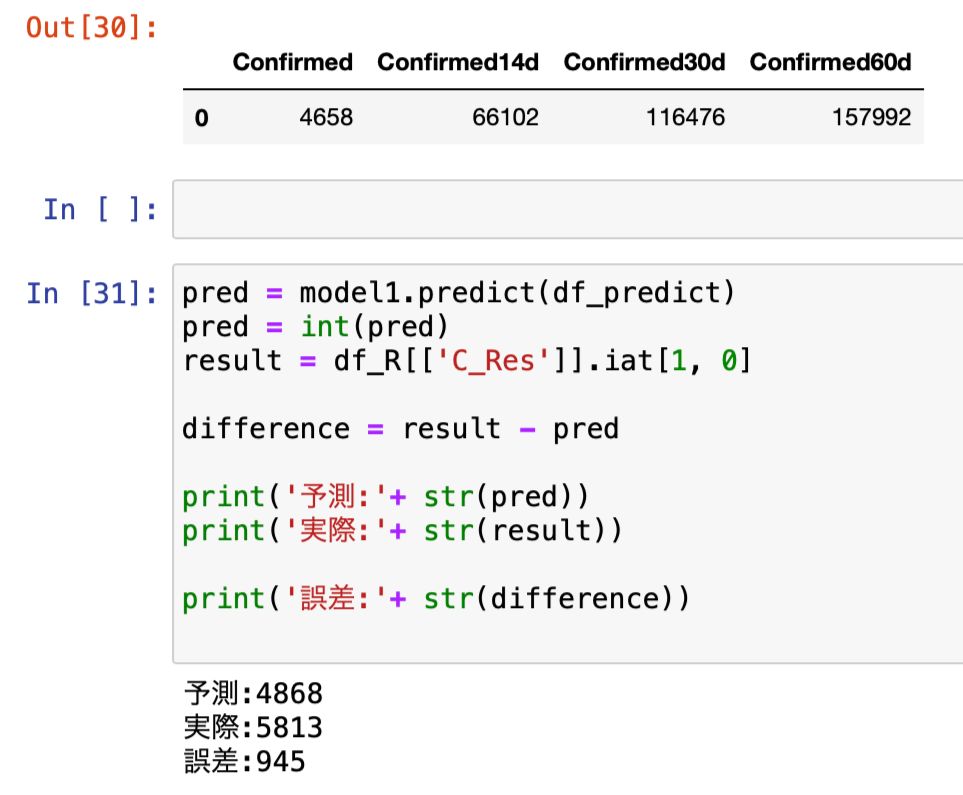
予測と実際の誤差は945人。
先の937人から僅かに悪化ですが、Ver1.00の1,151人依然として上回る結果です。
さらに期間の長い特徴量を追加してみます。
今度は日毎・14日毎・30日毎・60日毎に90日毎を特徴量に加えてみます。
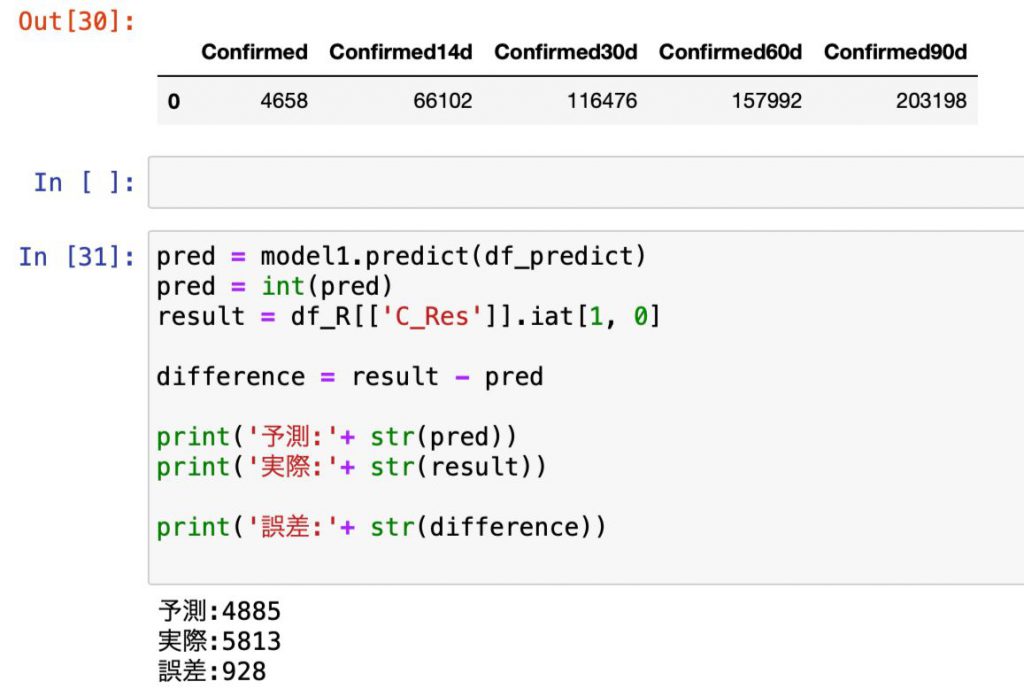
予測と実際の誤差は928人。
今度は前々回の937人、前回の945人を僅かながら上回る結果となりました。
方向性としては間違っていないように思います。
さらに長い期間の特徴量を加えてみることにします。
今度は日毎・14日毎・30日毎・60日毎・90日毎に120日毎を加えて6つの特徴量で予測を行います。
結果は以下のとおりとなりました。
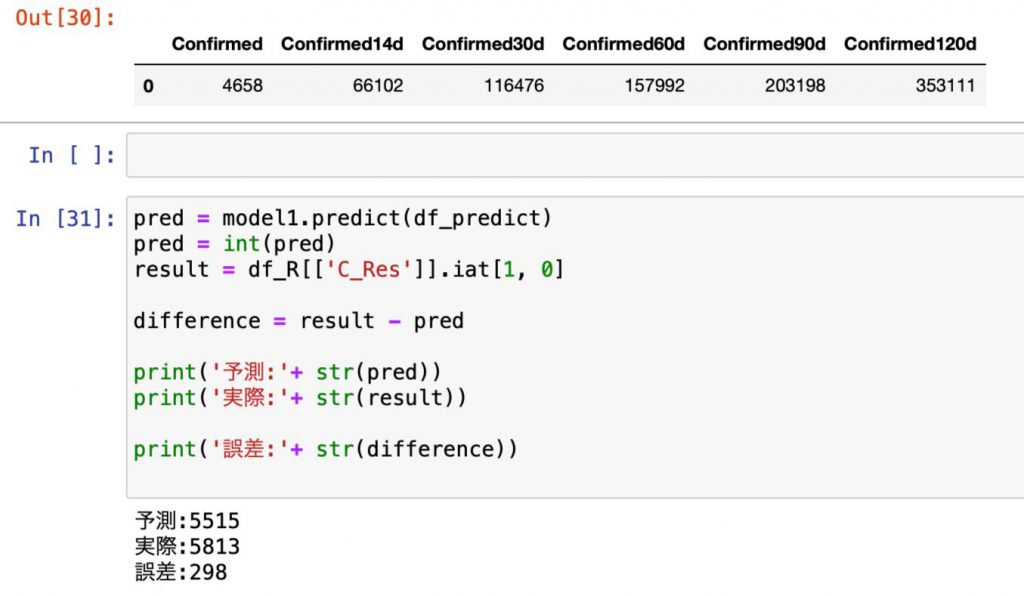
予測と実際の誤差は298人。
先の928人からは大躍進の結果となりました。
これなら予測と言えそうなレベルに近付いてきました。
さらに長い期間を特徴量に加えて、さらなる予測精度の改善を図りたいところですが、まだまだ長くなりそうなので、続きはPart2にて行いたいと思います。