前回、初めて行ったコンペティション参加の結果はランキング外となりました。
用意されたデータを、決まった手順で機械学習アルゴリズムにかけて、単純に予測させただけなので当然の結果かと思います。
逆に、これからどこまで順位を上げられるか楽しみでもあります。
予測精度を上げる方法は色々とあるようですが、今回は目的変数を増やしてみようと思います。
前回はloan_amnt・interest_rate・credit_scoreの3列が量的データだったので、これらを目的変数として使用しました。
この3つ以外にも、目的変数を増やしてみようというのが今回の試みとなります。
あらためてデータの内容を確認してみると、
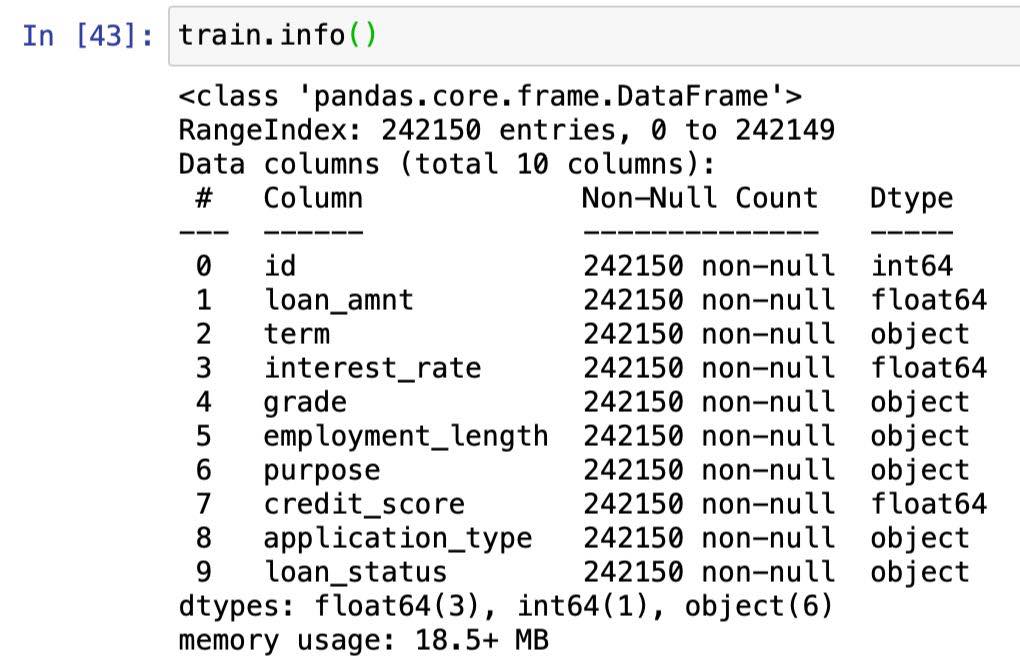
term・grade・employment_length・purpose・application_typeの5カラムが質的データとなっています。
これらをpd.get_dummies関数を使ってダミー変数化、量的データとします。
あとは前回と同じで順で、上記をtrain_test_split関数を使って学習用データ・評価用データに分割し、予測を行います。
f1_scoreを使って予測結果の評価を行うと以下の結果が表示されました。

前回の0.06999375055798589からほぼ倍のスコアに改善されました。
これはちょっと期待できそうです。
さっそく投稿してみます。
・・・・
結果はまたもやランキング対象外。
しかし、このランキングは当コンペティションのものではなく、総合的なもののようでした。
その為、リーダーボードを確認することにします。
結果は、
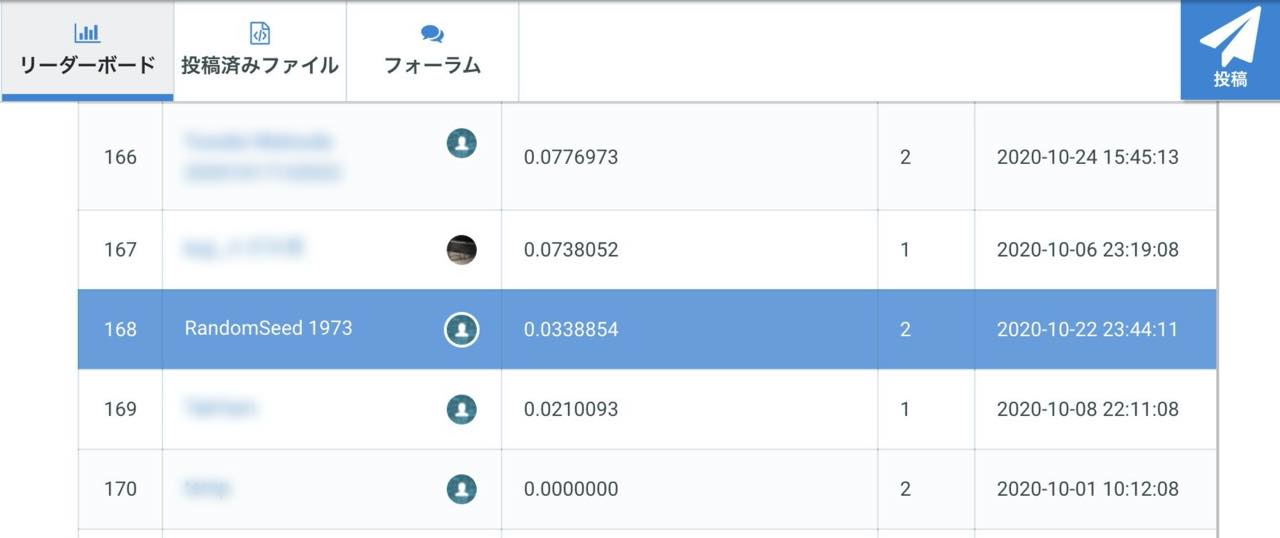
168位でした。
参加人数178人中なので下から10位。
惨憺たる結果となりました。
これはもうSIGNATEの有料オンライン講座に申し込むしかなさそうです。
というか、先程申し込みを行いました。
半年プラン6,578円。
しかし、本コンペティションに関しては、他にも試してみたいことがあるので、ランキング云々以前に、今の自分が機械学習で何が出来るのか、どこまでできるのかを残り10日間で試してみたいと思います。