Pythonによる機械学習でCIVID-19の感染者数を予測する試みも今回で三回目。
今回も重回帰モデルを用いて、当日の数字から翌日の数字の予測を行います。
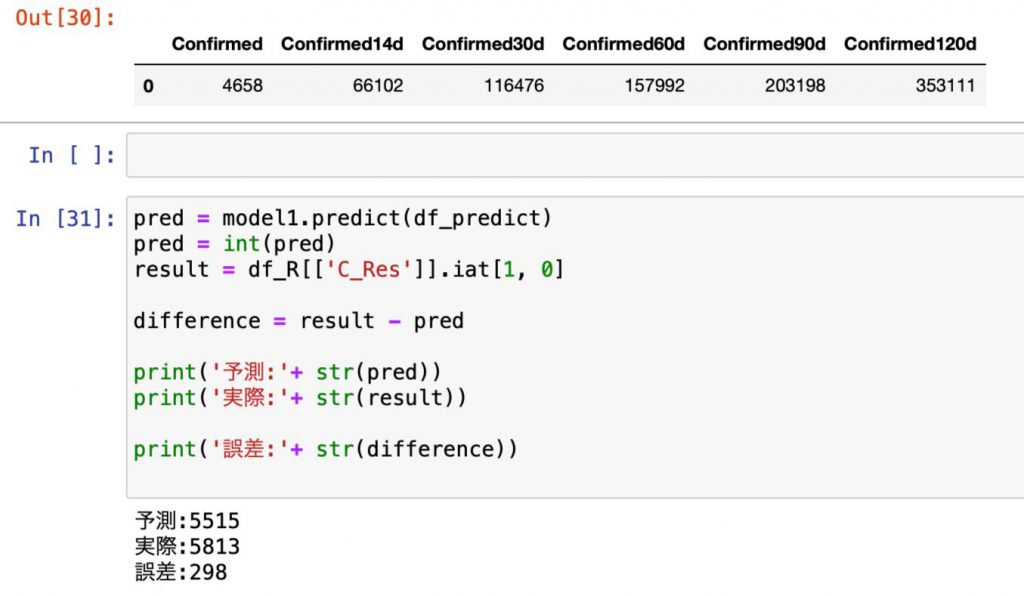
前回Part1では、期間の長い特徴量を追加することで、予測と実際の誤差を298人まで縮めることができました。
前回に引き続きVer1.02への改良を続けます。
今度は日毎・14日毎・30日毎・60日毎・90日毎・120日毎に150日毎(当日+直近過去149日)を加えて7つの特徴量で予測を行います。
予測と実際の誤差は258人。
前回の298人からさらに改善の結果となりました。
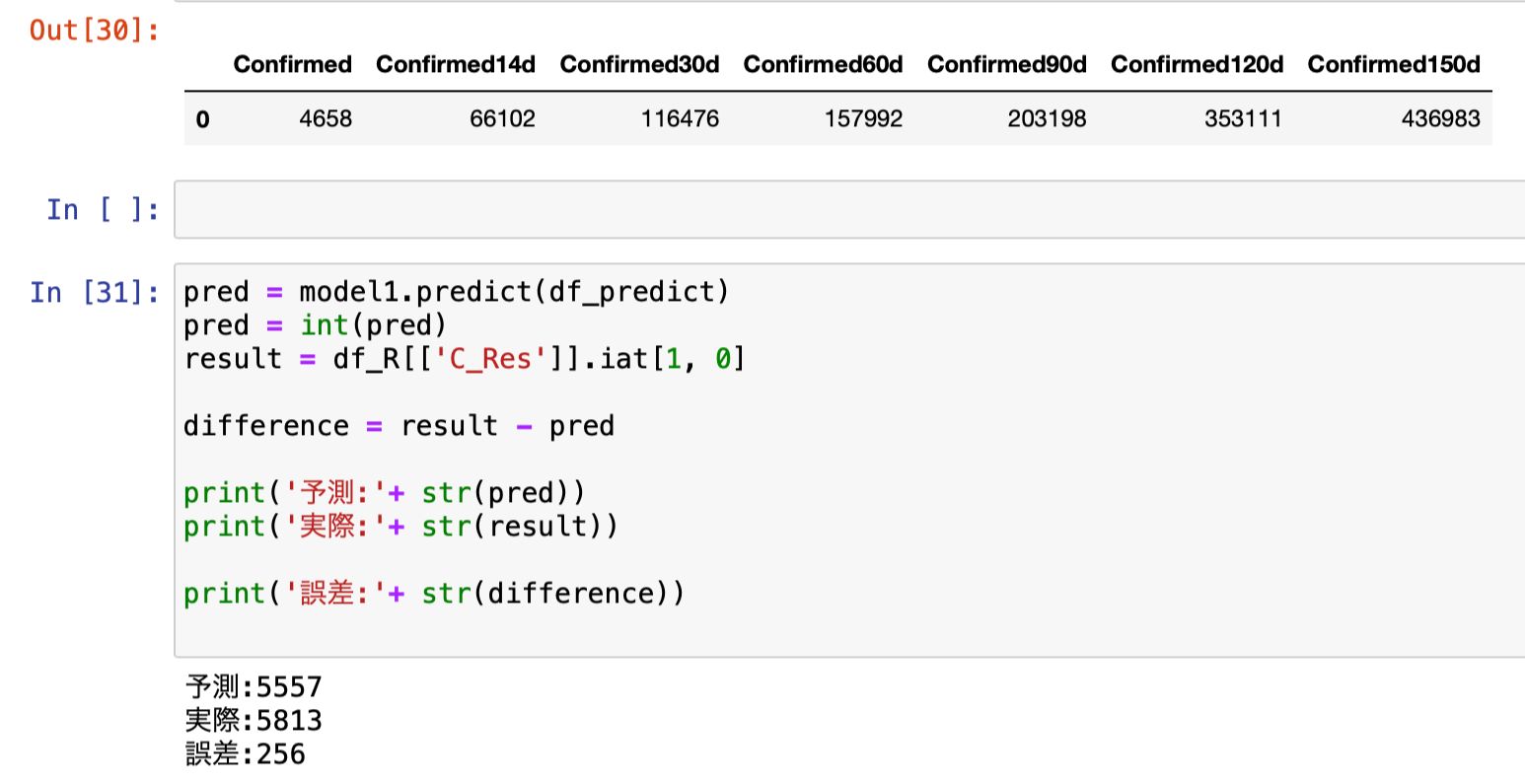
さらに日毎・14日毎・30日毎・60日毎・90日毎・120日毎・150日毎に180日毎(当日+直近過去179日)を加えて8つの特徴量で予測を行います。
予測と実際の誤差は182人。
前回の252人からさらに改善の結果となりました。
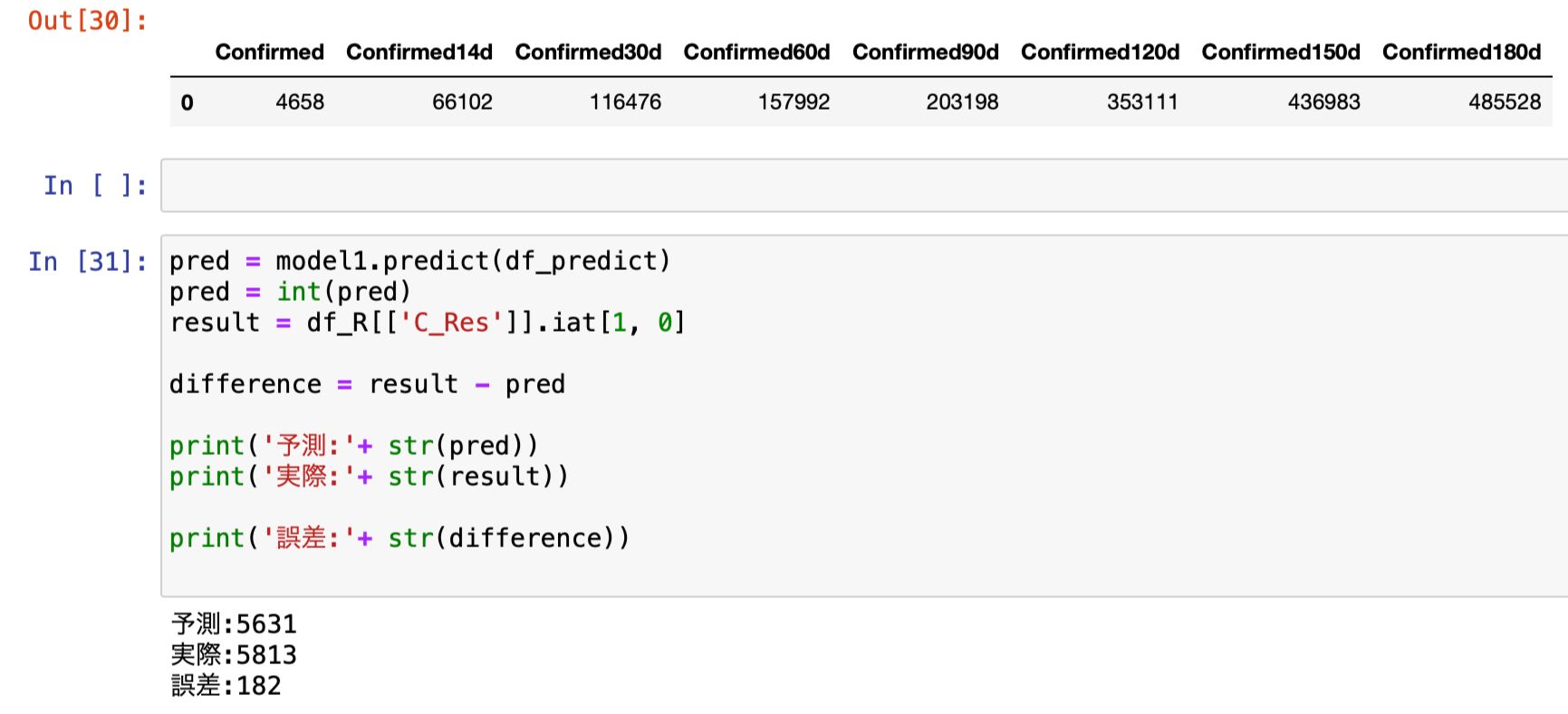
さらに日毎・14日毎・30日毎・60日毎・90日毎・120日毎・150日毎・180日毎に210日毎(当日+直近過去209日)を加えて9つの特徴量で予測を行います。
予測と実際の誤差は178人。
前回の182人から僅かながらの改善。
そろそろこの辺りが限界かもそれません。
しかし、試さずに決めつけるのは愚の骨頂なので、もう少し続けることにします。
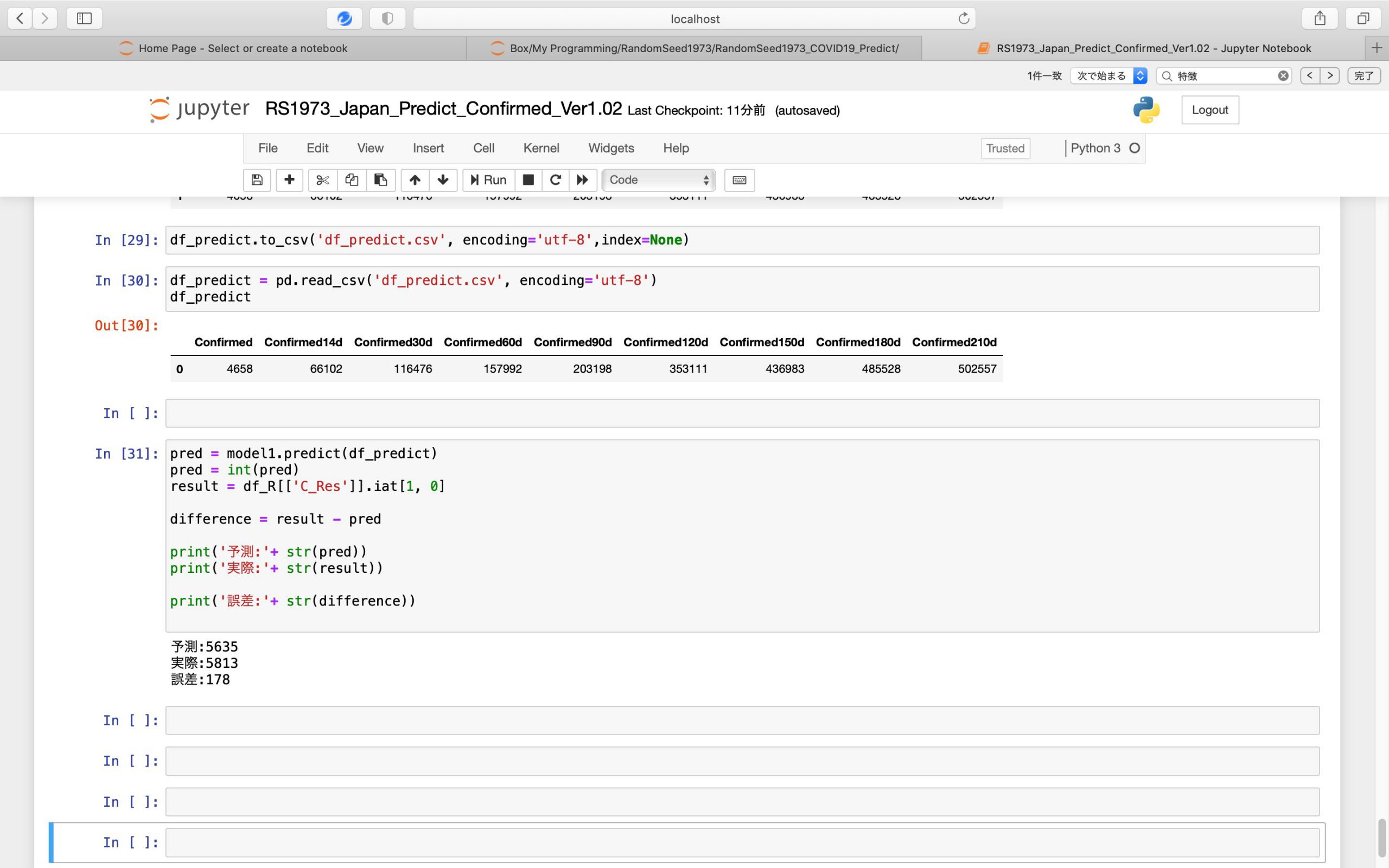
今度は日毎・14日毎・30日毎・60日毎・90日毎・120日毎・150日毎・180日毎・210日毎に240日毎(当日+直近過去239日)を加えて10つの特徴量で予測を行います。
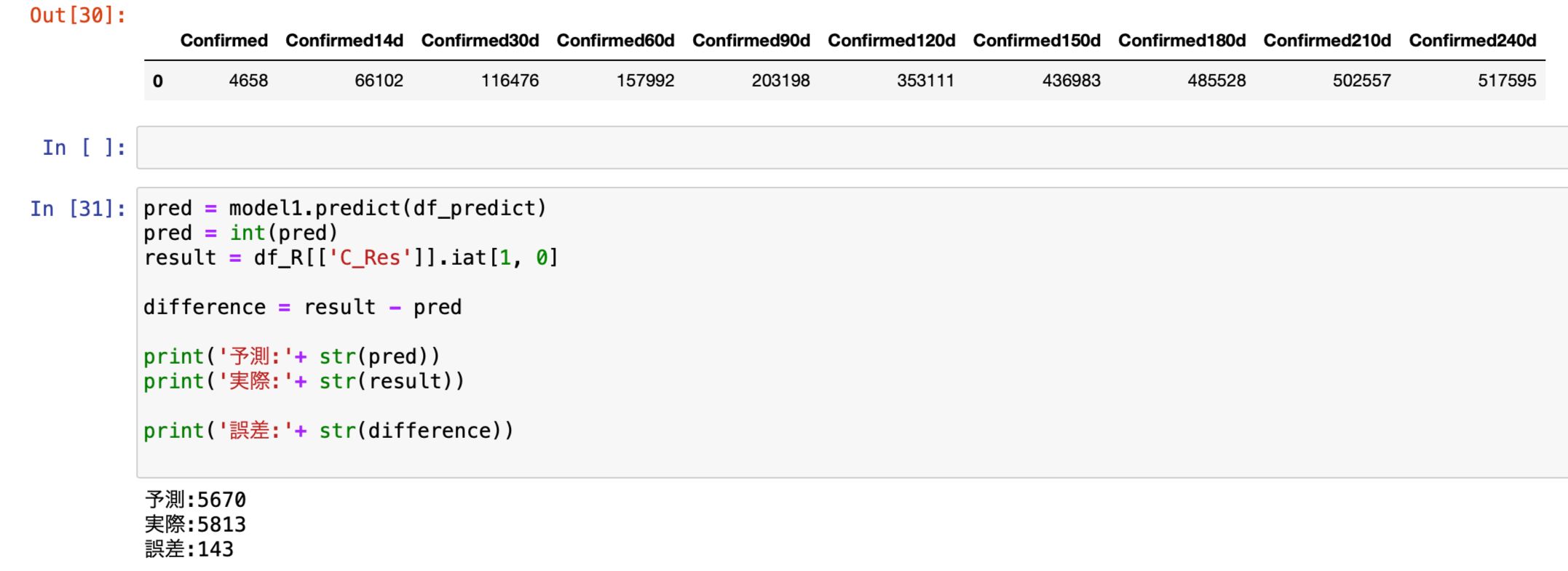
予測と実際の誤差は143人。
前回の182人からさらに改善の結果となりました。
さらに日毎・14日毎・30日毎・60日毎・90日毎・120日毎・150日毎・180日毎・210日毎・240日毎に270日毎(当日+直近過去269日)を加えて11つの特徴量で予測を行います。
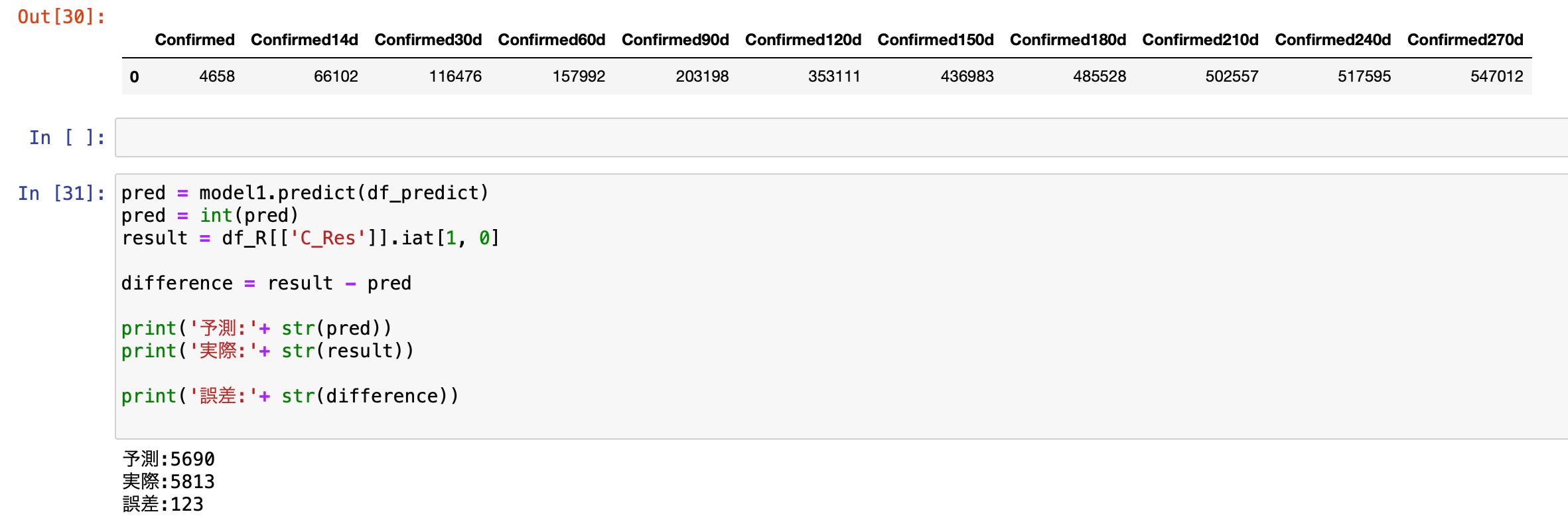
予測と実際の誤差は123人。
前回の178人から55人もの改善となりました。
このまま進めると二桁台も間近といった状況ですが、今回はこれまでに使用と思います。
そもそも380行のデータなので、これ以上長い期間での学習が有効なのか疑問です。
それ以前の問題として、今でさえ疑問符がつく状況です。
それに現在は5/1に対する予測を行っていますが、これが5/2以降のデータに対して有効化は未知数です。
5/2以降のデータに対しても、5/1同様か近い予測が行えれば、正しい方向性で進められているということになりますが、その逆もありえます。
次回Part3では5/2以降のデータでの予測を行い、いわゆる汎化性能の確認を行ってみようと思います。