前回に引き続き、今回も日本版(1)のデータの前処理編です。
前回は元データから「Date」「Confirmed」「Location」の3列を持つ47都道府県のデータフレームを作成し、リストに格納しました。
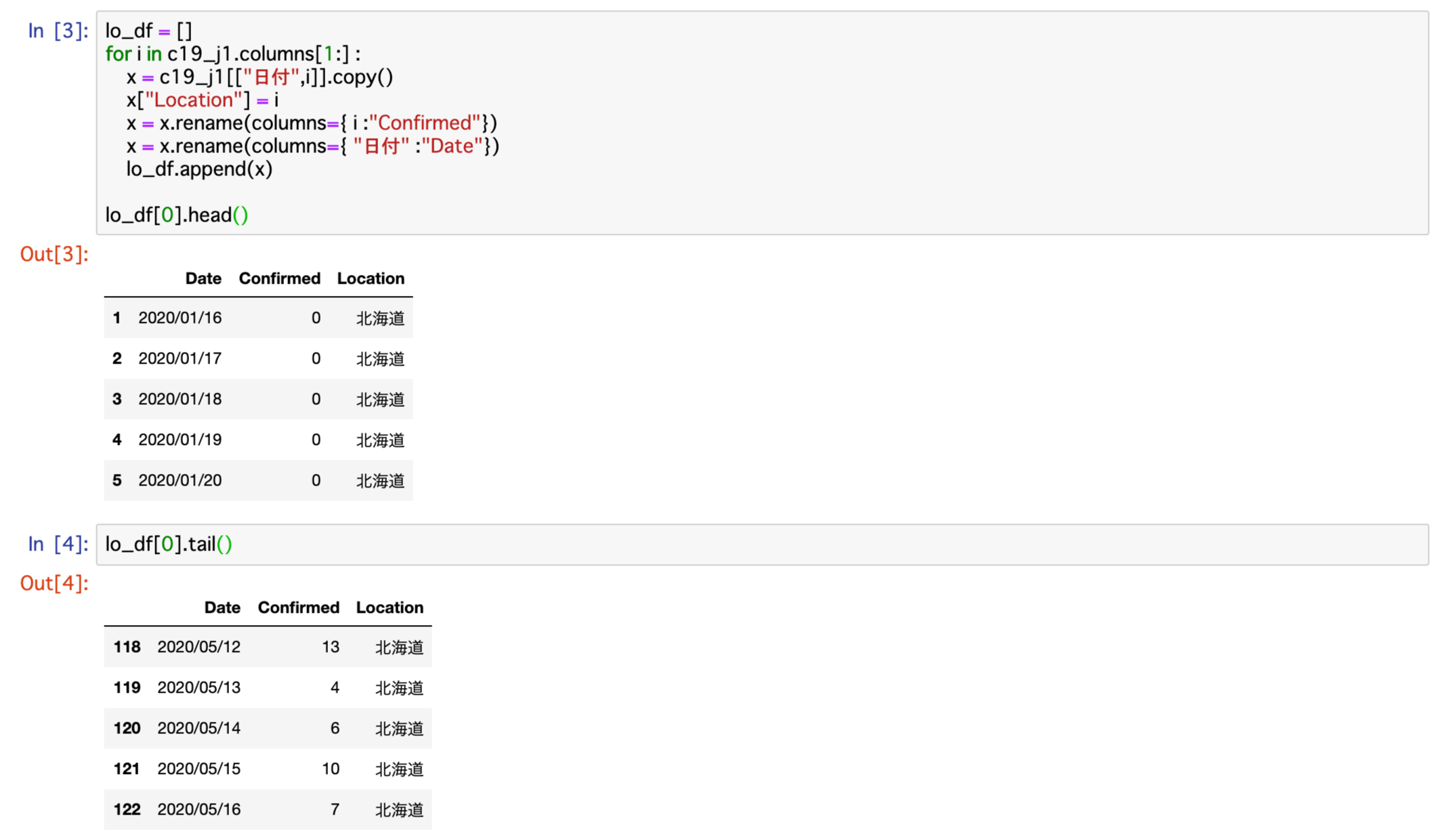
今回は、このリストに格納した47個のデータフレームを、Pandasのconcat関数を使って結合することにします
c19j1_df = pd.concat(lo_df , sort=False, ignore_index=True)
c19j1_df.head()
c19j1_df.tail()上記コードを実行したことろ、結果は以下のとおりになりました。
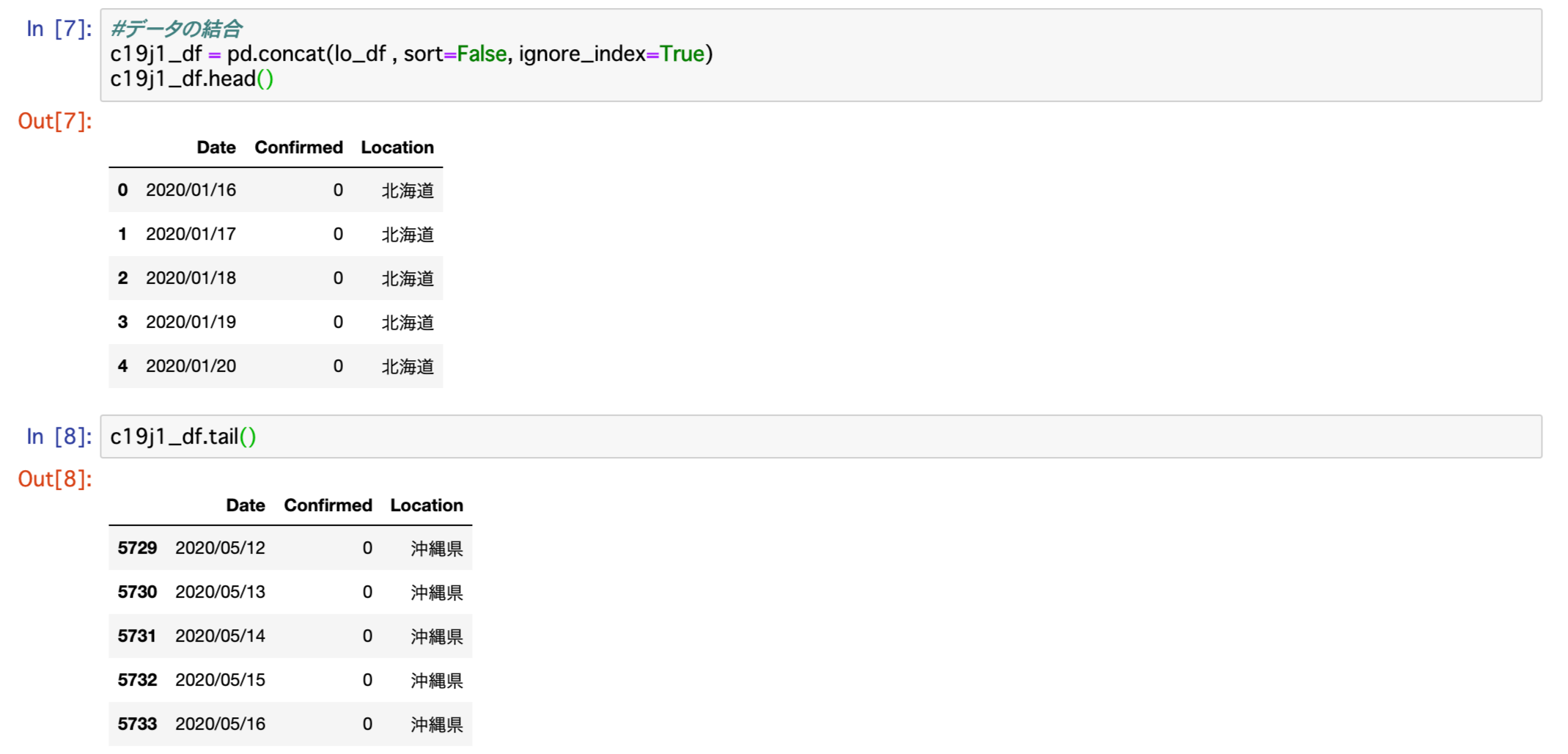
行の先頭が0スタートなので、末尾の行番号5733に1を加えた5737が、このデータの行数になり、それを都道府県数47で割ると122となります。
各都道府県のデータが122行だったので、問題なくデータが結合されていることが分かりました。
ここで少し気になったのがカラムの並びです。
これは主観の問題なのですが、個人的には「Date」「Confirmed」「Location」より「Location」「Date」「Confirmed」の方が分かりやすいように思われました。
c19j1_df = c19j1_df.reindex(columns=["Location","Date","Confirmed"])
c19j1_df.head()
c19j1_df.tail()上記コードを実行し内容を確認します。
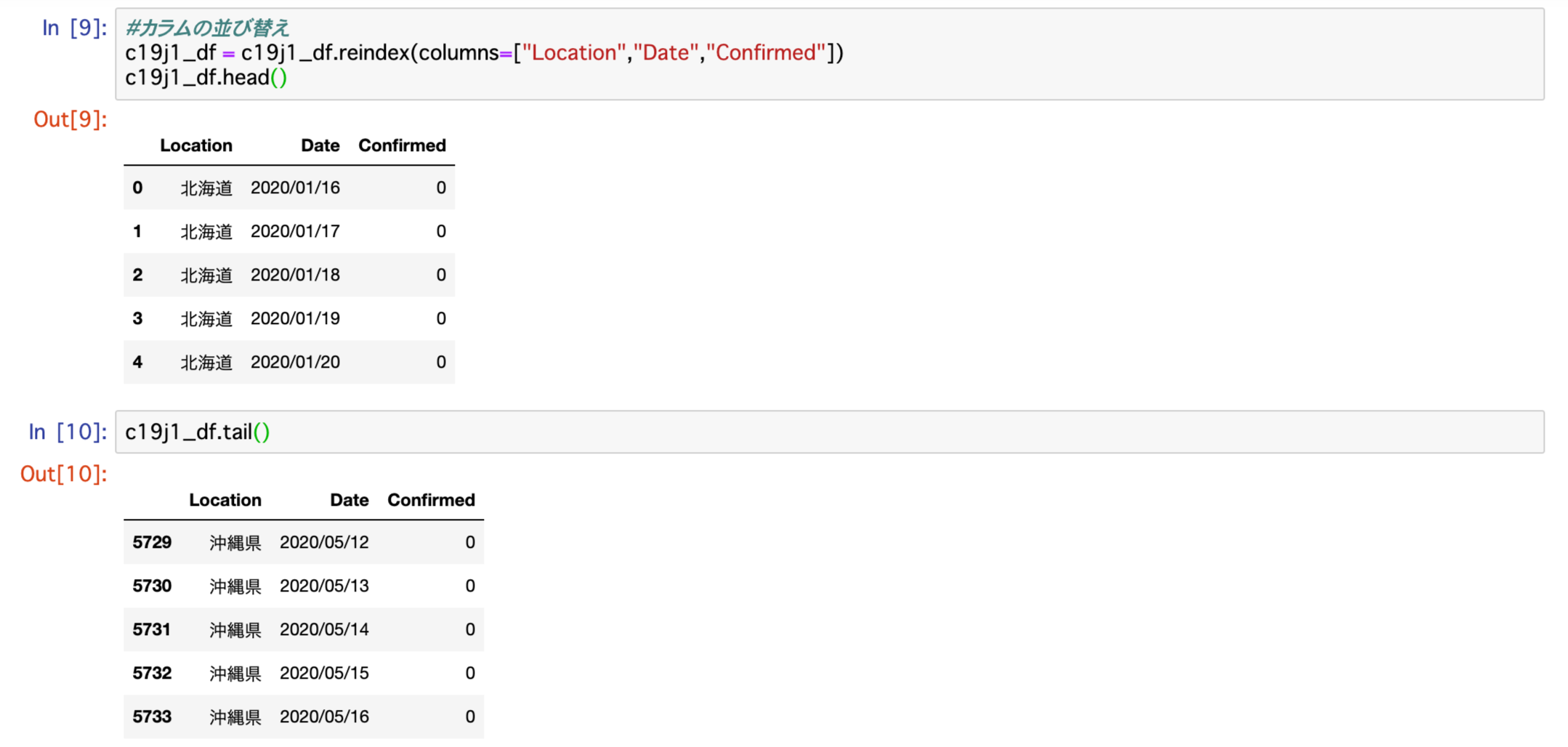
無事カラムがの並び替えが行われました。
念の為にデータの行数と欠損値の有無も再度確認しておくことにします。
len(c19j1_df)で行数を確認。

c19j1_df.isnull().sum()で欠損値の有無を確認。

どちらも問題にないことが確認できます。
ようやく希望するデータが完成しました。
次回はこのデータをcsvファイルに書き込みしようと思います。