いよいよ今回から分析編です。
SIGNATE COVID-19 Case Datasetからプログラムc19j1_df_ver1.0で作成したデータセットc19j1_dfを使って、今の私にできることを行ってみようと思います。
まずは日本全国の2020/01/16から2020/05/24時点の累計感染者数を表示してみようと思います。
c19j1_df["Confirmed"].sum()で『Confirmed』の列を合計した結果が以下になります。

2020/01/16から2020/05/24時点の日本全国の累計感染者数が16,276人だと分かりました。
次は2020/01/16から2020/05/24時点の都道府県別の累計感染者数を降順に表示てみようと思います。
Pandas の groupby を使って以下コードを実行します。
c19j1_df.groupby("Location").sum().sort_values(by='Confirmed',ascending=False) 結果は以下のとおりとなりました。
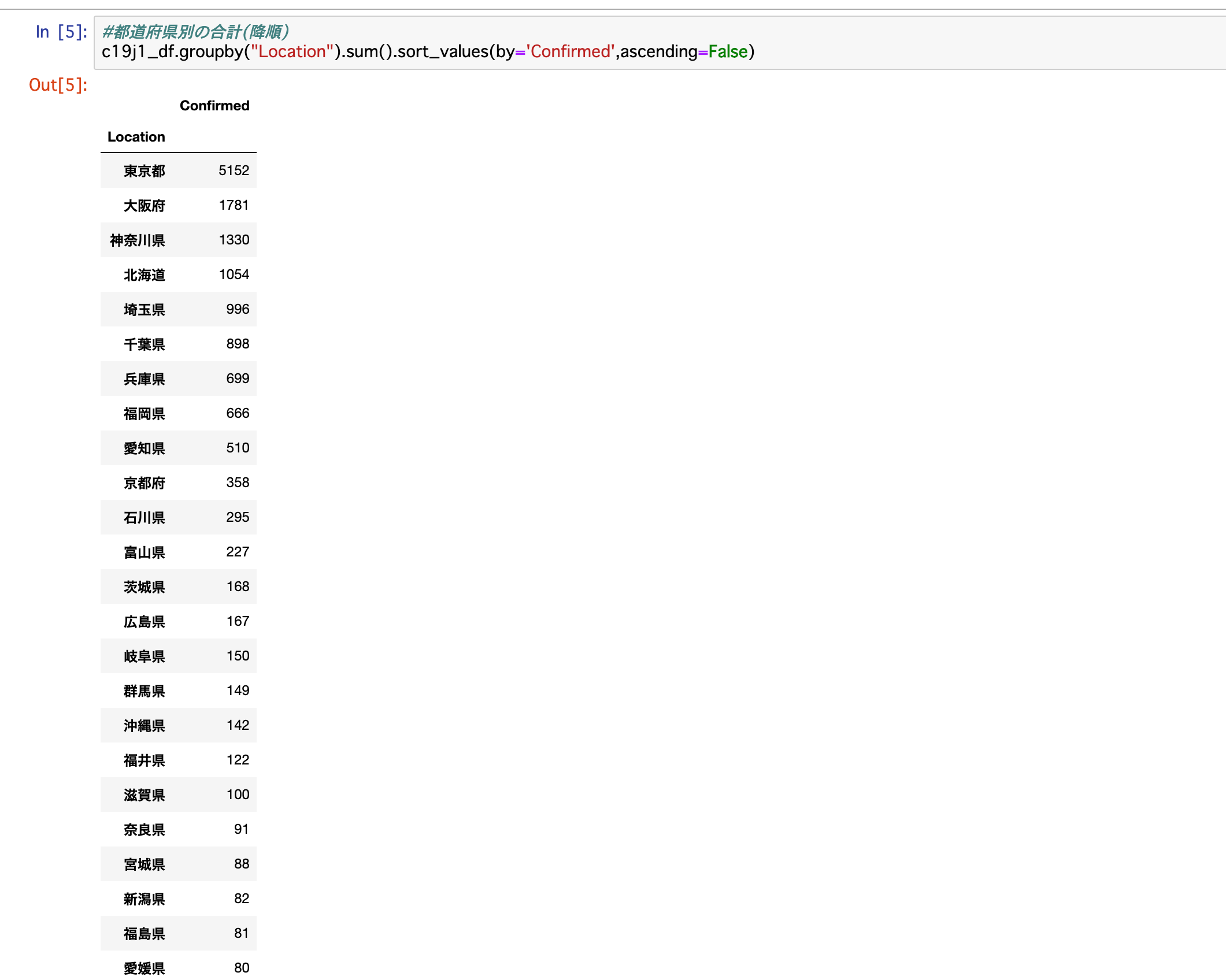

東京都の5,152人を筆頭に岩手県の0人までが表示されました。
東京都:5152
大阪府:1781
神奈川県:1330
北海道:1054
埼玉県:996
千葉県:898
兵庫県:699
福岡県:666
愛知県:510
京都府:358
・
・
・
青森県:27
岡山県:25
島根県:24
長崎県:17
宮崎県:17
秋田県:16
鹿児島県:10
徳島県:5
鳥取県:3
岩手県:0
どの都道府県で感染者数が多いのか少ないのかが一目瞭然です。
東京都、大阪府、神奈川県、北海道、埼玉県、千葉県、兵庫県、福岡県、愛知県、京都府がトップ10。
いづれも大都市があり、人口・人口密度が多いからだと思われます。
しかし、これはあくまでイメージでしかありません。
今後、人口や人口密度などのデータを付加して、具体的に数値として明示できたらと思っています。
次は日付別で日本全国の累計感染者数を調べてみようと思います。
今回もPandas の groupby を使いますが、今回はDate(日付)を元にConfirmed(感染者数)を集計します。
c19j1_df.groupby(["Date"]).sum()[["Confirmed"]].sort_values(by="Confirmed",ascending=False) 上記コードを実行した結果が以下となります。
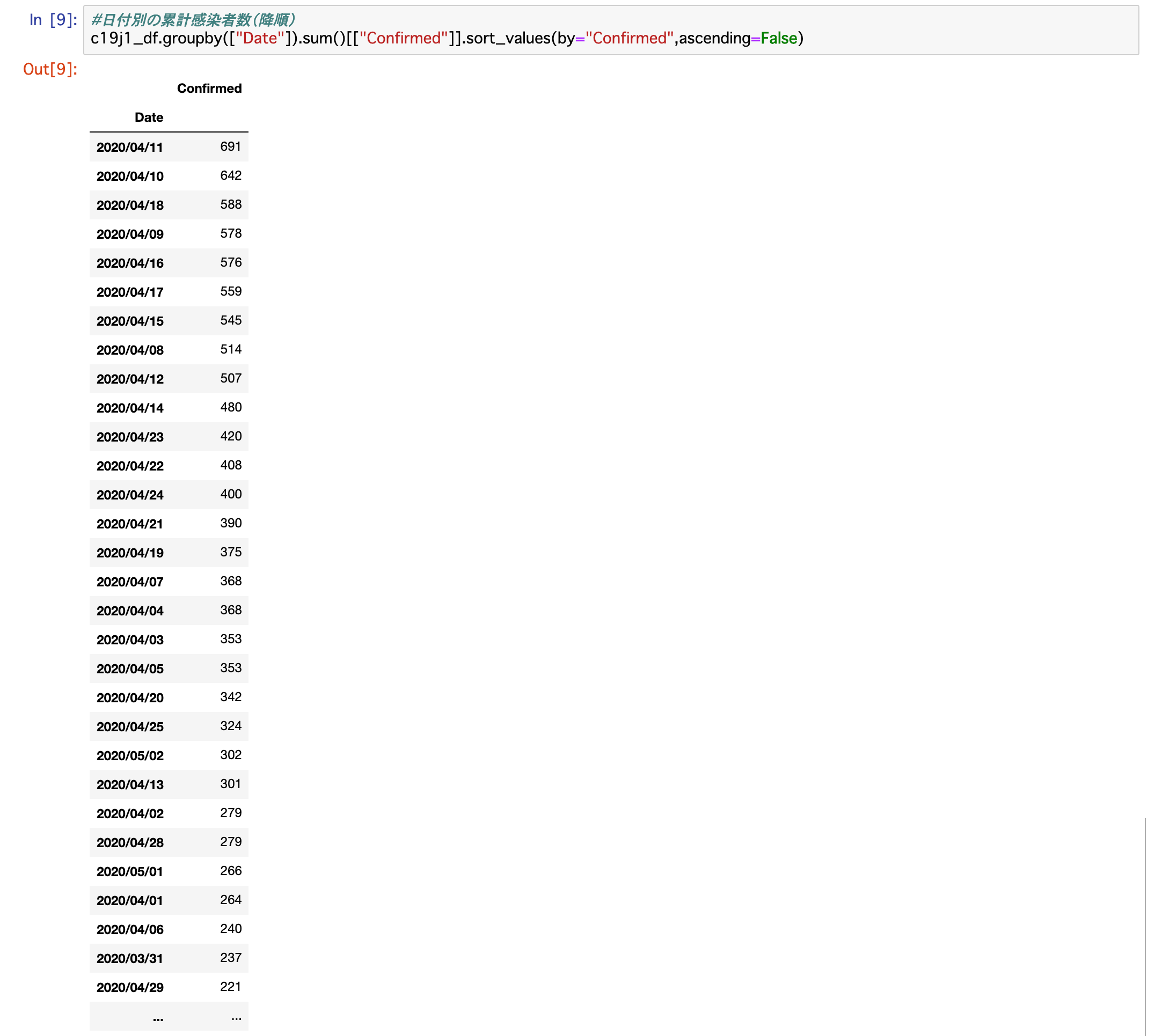

以下が感染者数の多かった日付の上位30日ですが、4月11日の691人を最高に、いずれも4月が上位を占めていることが分かります。
2020/04/11:691
2020/04/10:642
2020/04/18:588
2020/04/09:578
2020/04/16:576
2020/04/17:559
2020/04/15:545
2020/04/08:514
2020/04/12:507
2020/04/14:480
2020/04/23:420
2020/04/22:408
2020/04/24:400
2020/04/21:390
2020/04/19:375
2020/04/07:368
2020/04/04:368
2020/04/03:353
2020/04/05:353
2020/04/20:342
2020/04/25:324
2020/05/02:302
2020/04/13:301
2020/04/02:279
2020/04/28:279
2020/05/01:266
2020/04/01:264
2020/04/06:240
2020/03/31:237
2020/04/29:221
このデータは5月24日時点のもの。
それを踏まえた上で考えると、5月は、5月1日に302人、5月2日に266人で、それぞれ22位、26位でランクインしているものの、それ以降の日付は見当たりません。
日本全国に緊急事態宣言が発令され、ゴールデンウィーク中は外出自粛を余儀なくされましたが、結果はきちんと出ていると判断できます。
法的強制力のない中での、この結果は素晴らしいのではないでしょうか。
130日と行数が多い為、上位・下位の30行づつのみが表示され、中間部分が省略して表示されてしまっています。
全て表示する方法もありますが、これだと数字の羅列が長くなり視認性が悪くなってしまいます。
その為、この辺りはグラフによる視覚化を行い分析したいと思います。