Part8から引き続き、今回も分析編です。
Part8では日本全国の2020/01/16から2020/05/24時点の累計感染者数の分析を試みましたが、今回はさらに内容を掘り下げて分析してみようと思います。
Part8で日本全国の2020/01/16から2020/05/24時点の累計感染者数が16,276人だと分かりました。

今回はビニングを使って、どの数字の感染者が多いのかを調べてみようと思います。
ビニング(ビン分割)とは数値データを適当な境界で区切りカテゴリデータ化すること。
今回の場合、東京都の5000人台から岩手県の0人までと幅広いので、どう区切るのか悩みますが、まずは試みてみようと思います。
しかし、グループ化したデータフレームをLocation_dfに格納し、そこからConfirmedの列を抽出・分析したかったのですが、マルチインデックスになっているのかうまくできませんでした。
このあたり経験不足・勉強不足な感が否めませんが、今の私にできる方法で対処しようと思います。
その結果選択したのがLocation_dfを一旦csvファイルに書き込みし、そのcsvデータを読み込む方法です。
これだと問題なくビニングすることができました。
それぞれのコードは以下となります。
#ビニング用csv作成
Location_df = c19j1_df.groupby("Location").sum().sort_values(by='Confirmed',ascending=False)
Location_df.to_csv("Location_df.csv" , encoding = "utf=8")
Location_df = pd.read_csv("Location_df.csv" , encoding = "utf=8")#データのビニング(インデックス・昇順)
bi = pd.cut(Location_df["Confirmed"], [0, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 2000, 3000, 4000, 5000, 6000]).value_counts(sort=False)上記を実行し、表示された結果が以下となります。
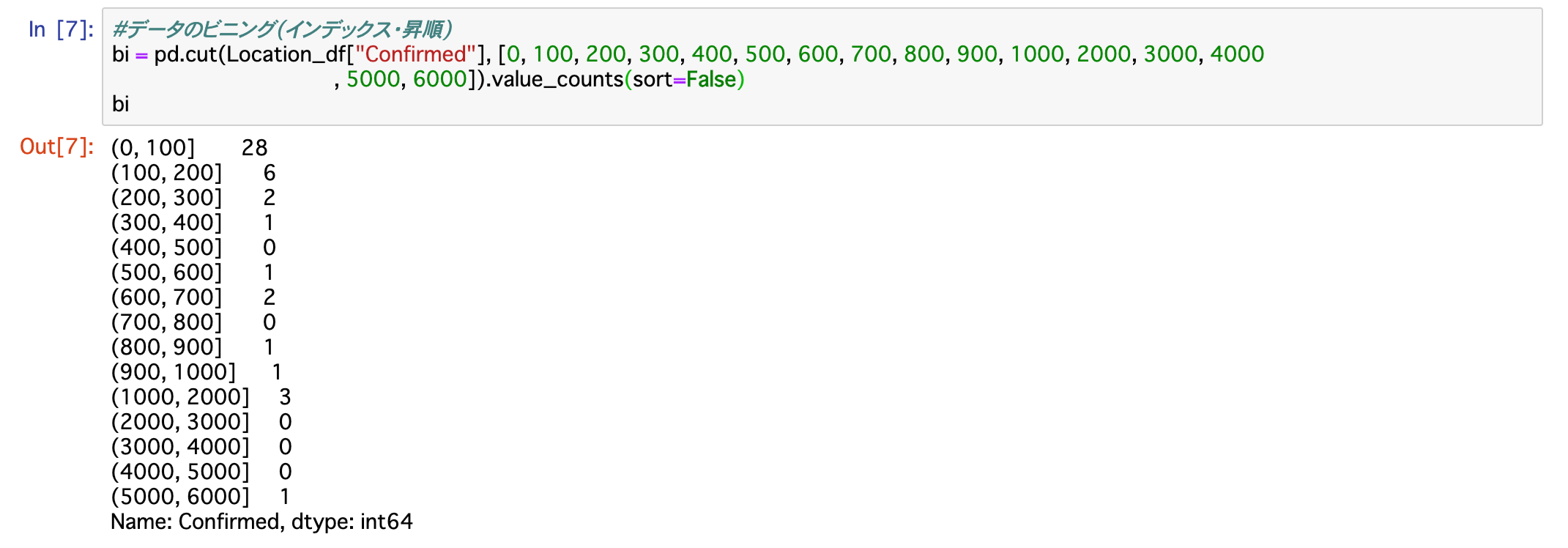
(0, 100] 28
(100, 200] 6
(200, 300] 2
(300, 400] 1
(400, 500] 0
(500, 600] 1
(600, 700] 2
(700, 800] 0
(800, 900] 1
(900, 1000] 1
(1000, 2000] 3
(2000, 3000] 0
(3000, 4000] 0
(4000, 5000] 0
(5000, 6000] 1
5000人台に東京都の1件がありますが、その次は1000人台の3件までと大きく開きがあります。
いかに東京都の感染者数が多いかが分かります。
感染率が高いことの証左でもあると思われます。
一方で100人以下が28件と47都道府県の中の半数上を締めてもいます。
こちらは感染率が低いことの証左で、それだけ感染する確率の高い都道府県とそうではない都道府県とが存在することでしょう。
このことは県をまたいでの移動は感染拡大を引き起こす可能性・危険性が高いことを示しているとも思われます。
まだしばらくは外出自粛、少なくとも県をまたいでの移動・外出は控えるべきででしょう。
感染者数で並べ替えが可能だったので、以下にその結果も掲載しておこうと思います。
こちらの方が状況を理解しやすいかと思います。
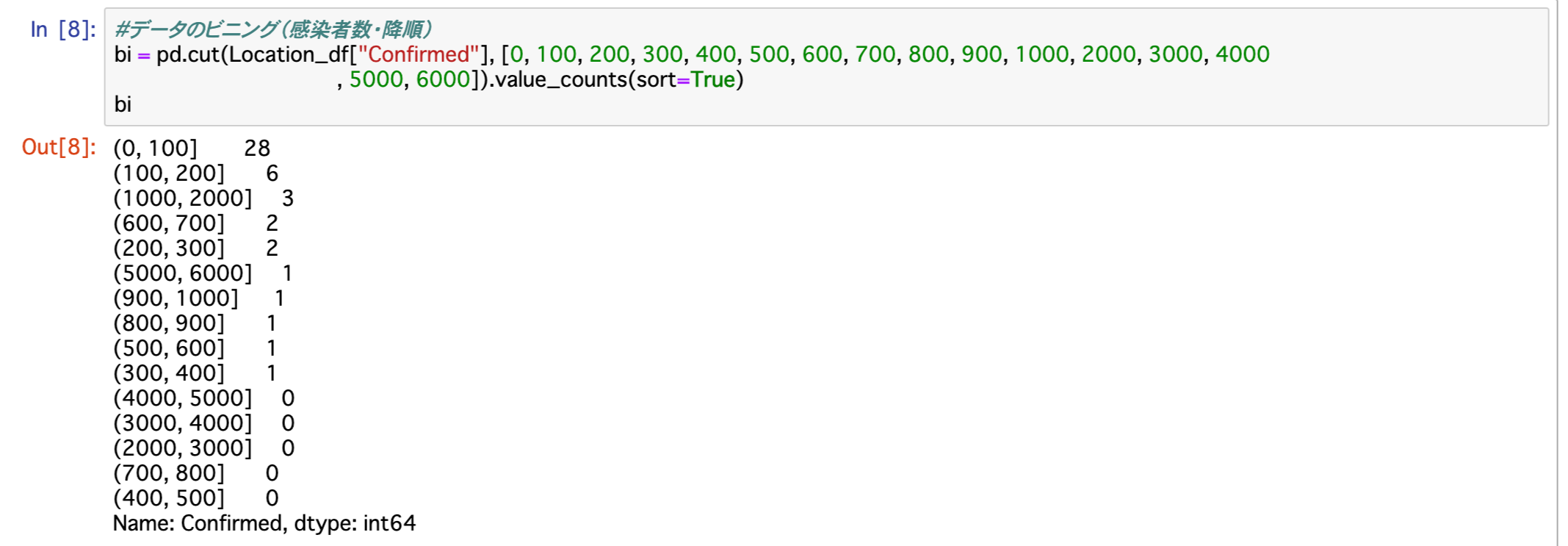
(0, 100] 28 (100, 200] 6 (1000, 2000] 3 (600, 700] 2 (200, 300] 2 (5000, 6000] 1 (900, 1000] 1 (800, 900] 1 (500, 600] 1 (300, 400] 1 (4000, 5000] 0 (3000, 4000] 0 (2000, 3000] 0 (700, 800] 0 (400, 500] 0