前回に引き続き世界版のデータの前処理を続けます。
前回、列Country/Regionに同じ名前の国が複数行が存在することが分かりました。
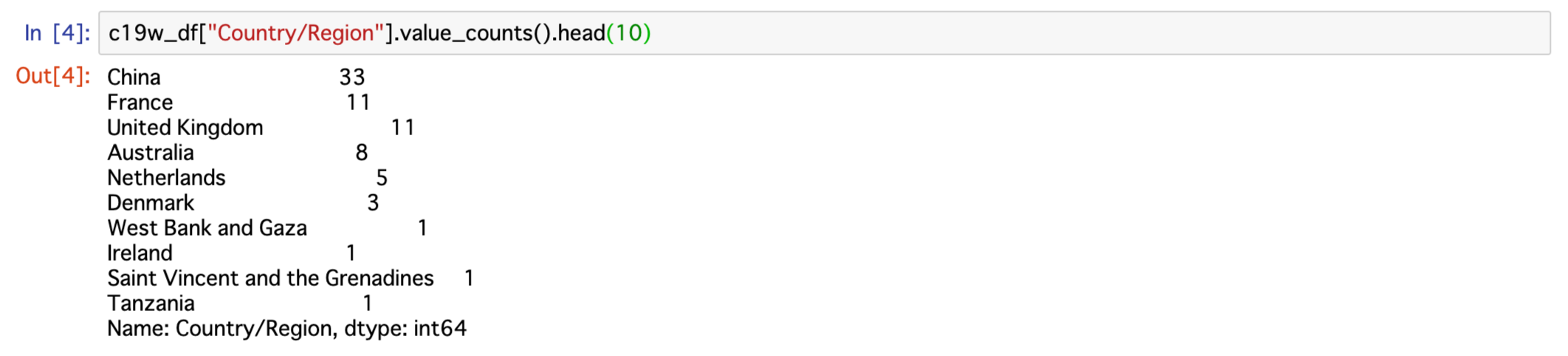
これは列Province/Stateが存在し、それらの国々に関しては記載があることから、州・県別に集計されていることを意味します。
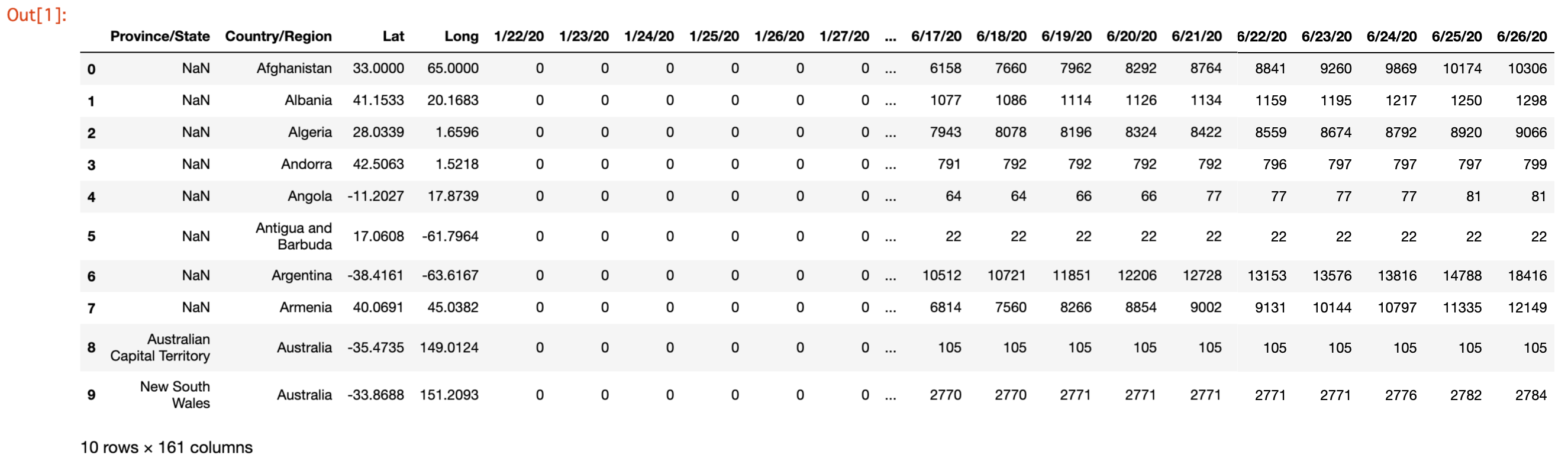
国毎のデータが必要なので、これらの国々に関しては州・県別になっている数字を合計する必要があります。
まずはChinaから合計処理を行います。
データフレームからChinaのみを抽出し、数字の合計を行います。
合計にはgroupbyメソッドを用います。
#Chinaのみを抽出
China_df = c19w_df.loc[c19w_df["Country/Region"] == "China"]
China_df.head()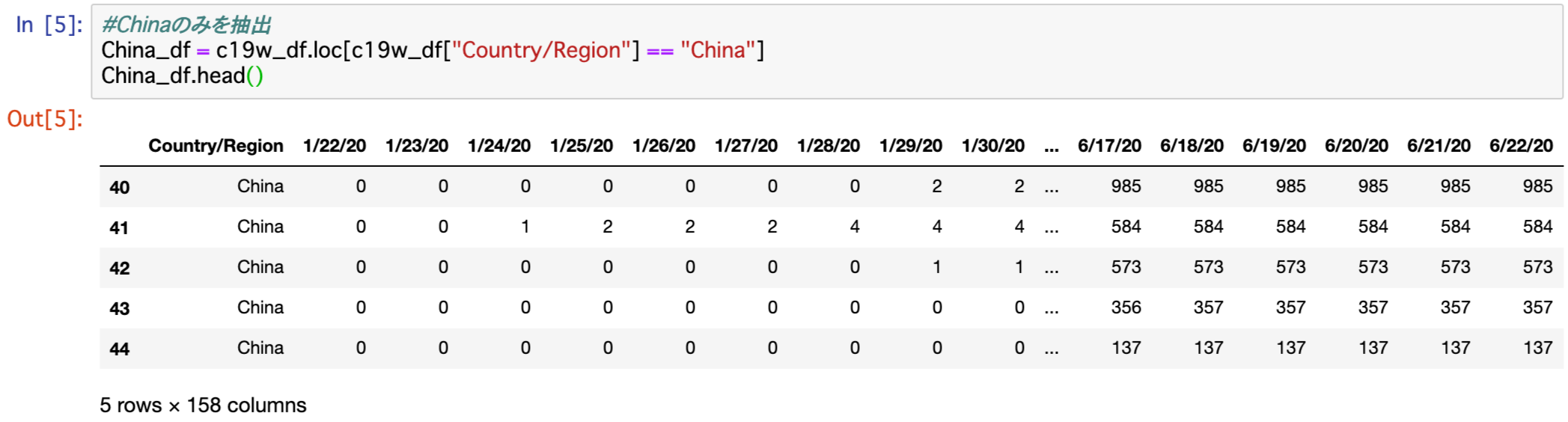
Chinaのみ抽出できているか確認しておきます。
Chinaは先に調べた時、33ありました。
#列のカウント
China_df["Country/Region"].value_counts()
33行であることが確認できました。
さらにこれらの行の合計をgroupbyメソッドで行います。
#数字の合計
China_df = China_df.groupby(["Country/Region"]).sum()
China_df
無事、合計することができました。
これでChinaのデータセットChina_dfが完成しました。
まだ先は長いので今回はここまでにしたいと思います。
次回は、テストでデータセットc19w_dfに今回作成したデータセットChina_dfを結合してみようと思います。