前回に引き続き世界版のデータの前処理を続けます。
今回は前回作成したデータセットChina_dfを元データc19w_dfに結合したいと思います。
以前にもありましたが、このままだとうまく結合ができません。
また、解決策も見つからないことから、以前の解決策、一旦csvファイルに書き込んでから再度読み込みという方法で行うことにします。
#China_dfのcsvファイルへの書き出し・再読み込み
China_df.to_csv("China_df.csv", encoding = "utf=8")
China_df2 = pd.read_csv("China_df.csv", encoding = "utf=8")
China_df2.head()
#c19w_dfのcsvファイルへの書き出し・再読み込み
c19w_df.to_csv("c19w_df.csv", encoding = "utf=8")
c19w_df2 = pd.read_csv("c19w_df.csv", encoding = "utf=8", index_col=0)
c19w_df2.head()
さらに上記データセットChina_df2とc19w_df2をpd.concatで結合します
#データの結合
c19w_df = pd.concat([China_df2,c19w_df2])
c19w_df.head()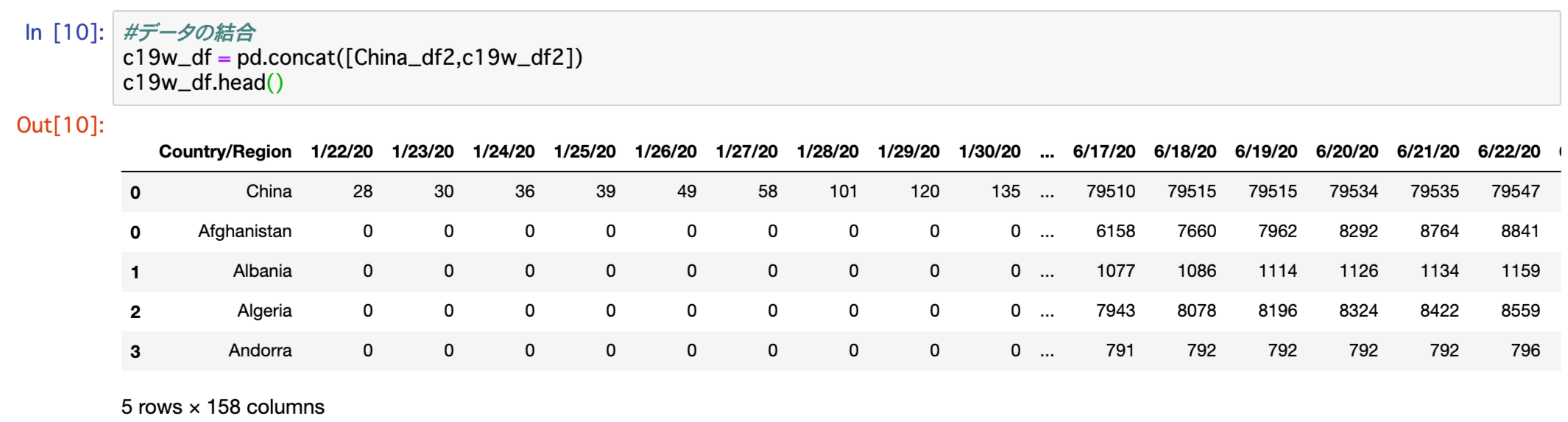
問題なくデータの結合が行えました。
データセットChina_df2の下にデータセットc19w_df2が結合されています。
さらにChinaの行数を確認しておきます。
元は33行でしたので、34行になっていればOKです。
以下コードを実行しChinaだけを抽出してから行数をカウントします。
#データの結合の確認
China_df = c19w_df.loc[c19w_df["Country/Region"] == "China"]
China_df["Country/Region"].value_counts()
予定通り34行になっていることが確認されました。
理論的には他の複数行存在する国々にも同様の処理を行い、今回はテストなので削除する前に結合を行いましたが、実際はデータセットc19w_dfから該当国を削除した後に結合をすれば各国ごとの日別の累計が揃ったデータセットができあがります。
次回以降、順次それらを行っていこうと思います。