前回に引き続き世界版のデータの前処理を続けます。
前回は本番前のテストとして作成したデータセットChina_dfをデータセットc19w_dfに結合するところまでを行いました。
理論的には他の列Country/Regionに同じ国名が複数行存在する国々に同じ処理を行い、それらの国々を削除したデータセットc19w_dfに結合すれば、必要としたデータセットができあがることになります。
復習も兼ねて列Country/Regionに同じ国名が複数行存在する国々を確認します。
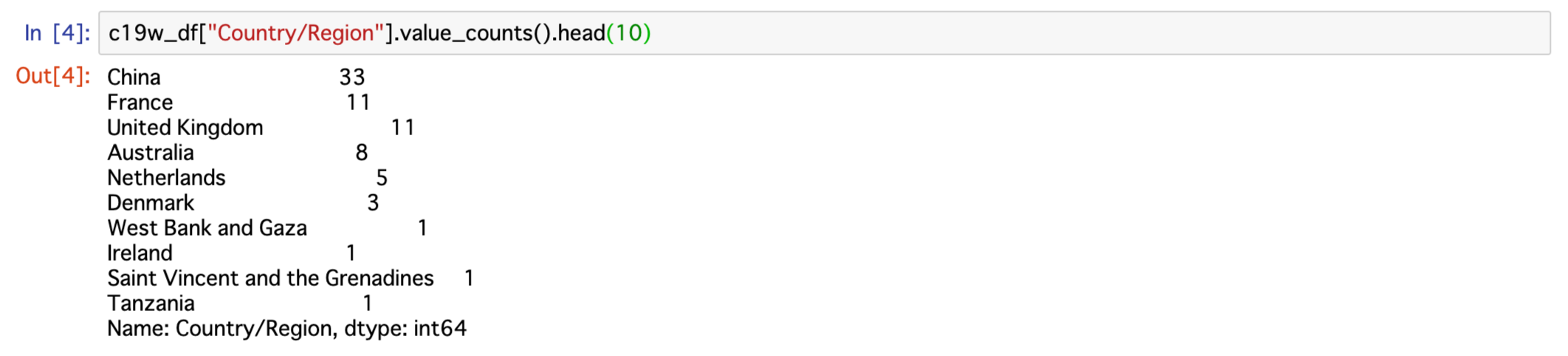
China・France・United Kingdom・Australia・Netherlands・Denmarkの六カ国が該当する国々でした。
ますは先のプログラムの出力内容を利用して国名リストsclを作成します。
以下コードでChina・France・United Kingdom・Australia・Netherlands・Denmarkの六カ国の国名リストsclを作成します。
#value_countsのデータから同じ名前が複数ある国の選択
scl = c19w_df["Country/Region"].value_counts().head(10)
scl = scl.index[0:6]
scl
さらに先程作成した国名リストsclをfor文で回し、六カ国分のそれぞれ合計データフレームを作成。
それらをcsvファイルに書き込みしてから、再度データフレームに読み込みします。
#列Country/Regionに同じ国名が複数ある国の抽出・csv書き込み・再読み込み
for sc in scl:
sc_df = c19w_df.loc[c19w_df["Country/Region"] == sc]
sc_df = sc_df.groupby(["Country/Region"]).sum()
sc_df.to_csv(""+ sc + "_df.csv", encoding = "utf=8")
sc_df2 = pd.read_csv(""+ sc + "_df.csv", encoding = "utf=8")
これで準備が整いました。
コードに問題がなければ、六カ国分のデータフレームができあがっているはずです。
順に呼び出して確認してみます。
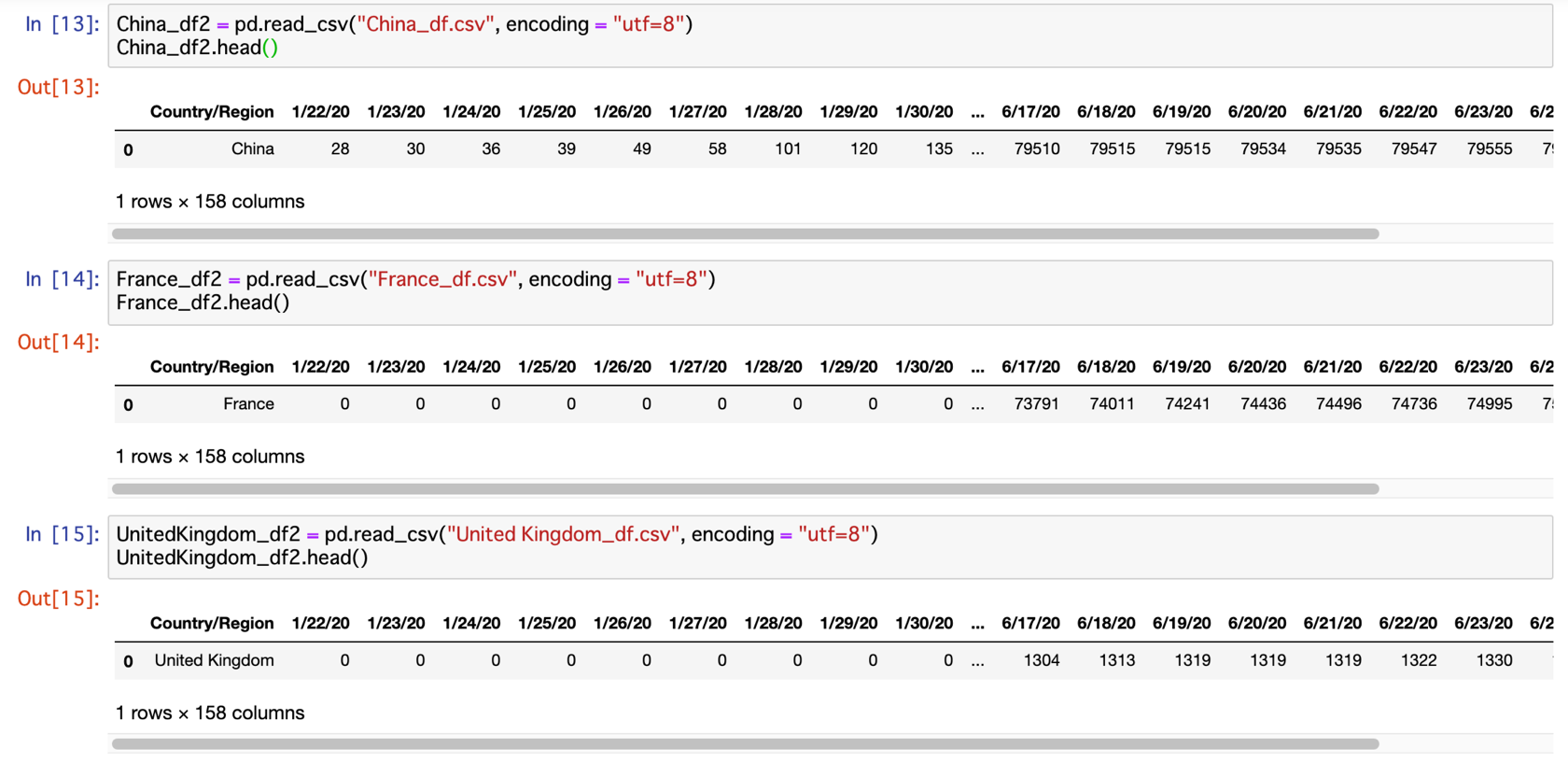

六カ国分のデータが問題なく処理され、データプレームかされているのが確認できました。
これで結合するデータが揃いました。
今度は元データセットc19w_dfから上記の六カ国を削除します。
内容の比較をする為、削除前の内容を確認してから削除を行います。
#削除前のデータ内容の確認
c19w_df.info()
#結合予定6カ国の行をオリジナルデータからの削除
c19w_df = c19w_df[c19w_df["Country/Region"] != "China"]
c19w_df = c19w_df[c19w_df["Country/Region"] != "United Kingdom"]
c19w_df = c19w_df[c19w_df["Country/Region"] != "France"]
c19w_df = c19w_df[c19w_df["Country/Region"] != "Australia"]
c19w_df = c19w_df[c19w_df["Country/Region"] != "Netherlands"]
c19w_df = c19w_df[c19w_df["Country/Region"] != "Denmark"]
c19w_df.info()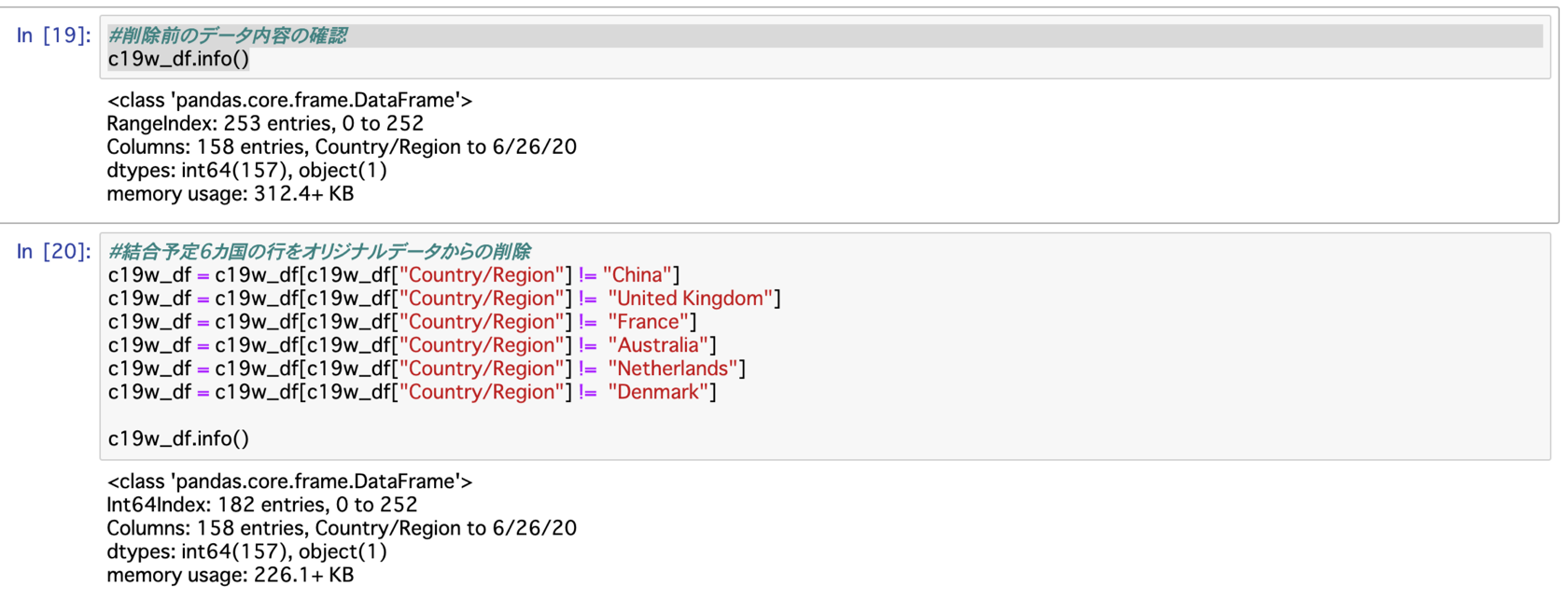
列Country/Regionに同じ国名が複数行存在する国は以下通り
China 33
United Kingdom 11
France 11
Australia 8
Netherlands 5
Denmark 3
六カ国分を合計すると71行でした。
変換前の行数は253行
返還後の行数は182行
返還前から返還後を引き算すると
253−182=71
となり上記と同じ71行となり、問題なく削除が行われていることが確認できました。
念の為に、列Country/Regionに同じ国名が複数行存在する国が残っていないかも確認しておきます。
#結合予定6カ国のオリジナルデータからの削除の確認
c19w_df["Country/Region"].value_counts().head(10)
これで列Country/Regionに同じ国名が複数行存在する国が残っていないことが確認できました。
いよいよデータの結合ですが、長くなったので次回に行おうと思います。