前回に引き続き世界版のデータの前処理を続けます。
前回は列Country/Regionに同じ国名が複数行存在する国をそれぞれ合計し、データセットを作成、さらにデータセットc19w_dfからそれら六カ国を削除するところまでを行いました。
今回はいよいよそれらのデータセットを結合しようと思います。
結合の前にcsvファイルへの書き出し、再読み込みを行います。
これを行わないと私の場合、結合がうまく行えません。
#c19w_dfのcsvファイルへの書き出し・再読み込み
c19w_df.to_csv("c19w_df.csv", encoding = "utf=8")
c19w_df2 = pd.read_csv("c19w_df.csv", encoding = "utf=8", index_col=0)
c19w_df2.head()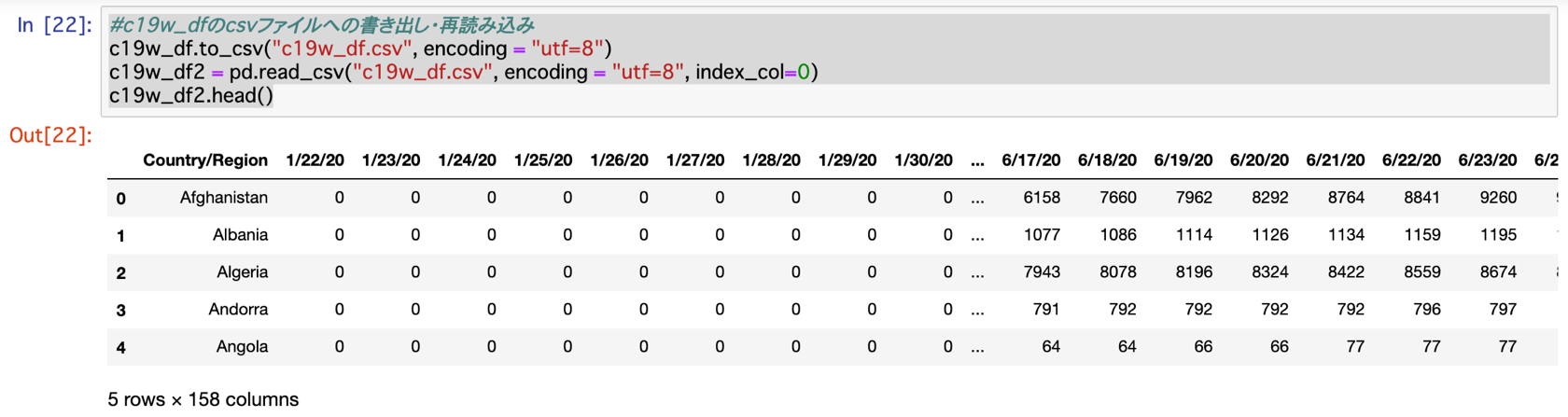
準備が整ったので、データの結合を行います。
データの結合にはconcatメソッドを使用します。
#合計データとオリジナルデータの結合
c19w_df3 = pd.concat([China_df2, UnitedKingdom_df2, France_df2, Australia_df2
, Netherlands_df2 , Denmark_df2 , c19w_df2], axis=0)
c19w_df3.head(10)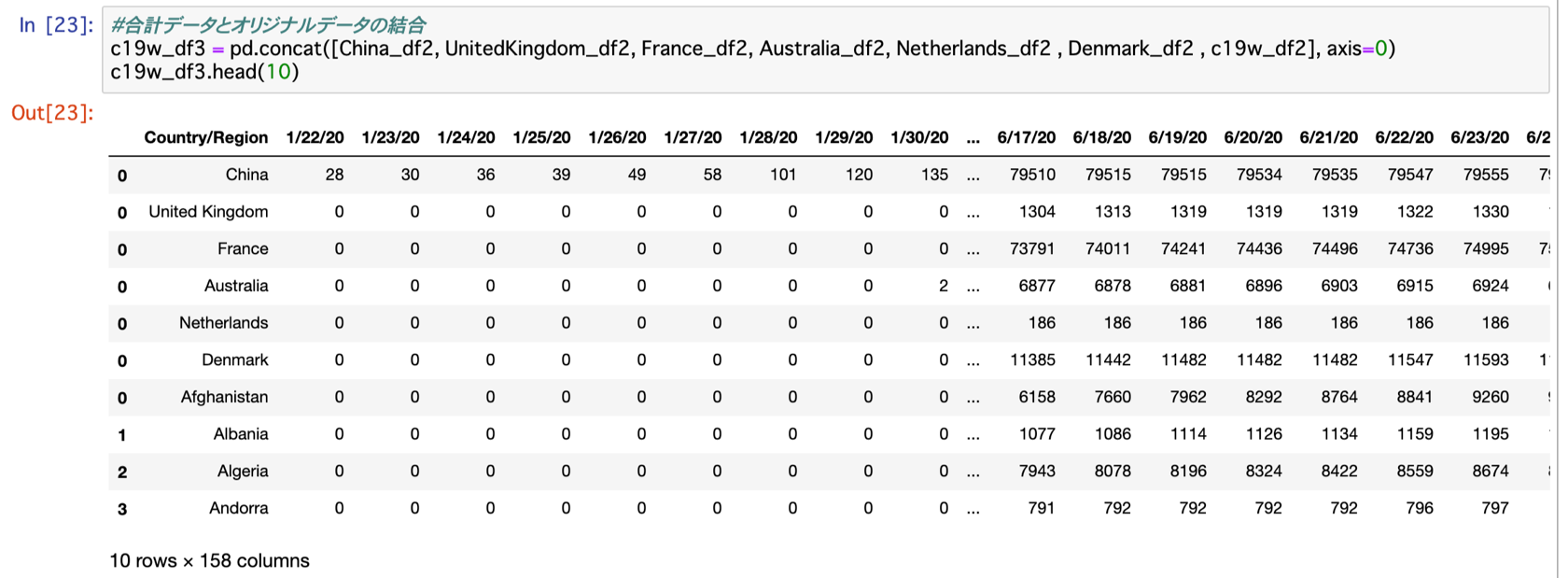
データセットc19w_df2の上に結合したChina・France・United Kingdom・Australia・Netherlands・Denmarkの六カ国が表示されていることから、データの結合がうまくいったことが確認されます。
念の為にデータの内容を確認しておきます。
結合前は182行×252列のデータでした。
このデータに6行を追加するので188行×252列のデータになっていれば問題のないことが確認できます。
以下のコードで確認を行います。
c19w_df3.info()
問題なく188行×252列のデータになっています。
さらにこのデータの行と列を入れ替え(転置)を行います。
方法は簡単でT属性を使用します。
データフレームの後ろに .T を記述すれば完了です。
今回はc19w_df3なのでc19w_df3.Tになります。
#行と列の変換
c19w_df4 = c19w_df3.T
c19w_df4.head()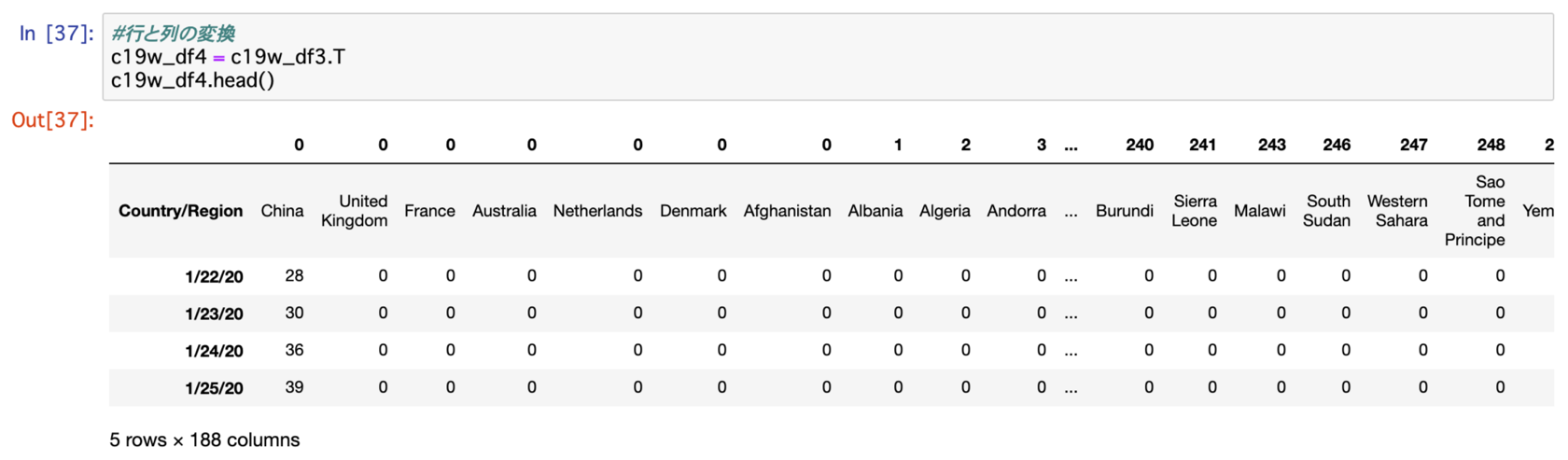
さらに、にcsvファイルへの書き出し、再読み込みを行います。
#c19w_df4のcsvファイルへの書き出し・再読み込み
c19w_df4.to_csv("c19w_df4.csv", encoding = "utf=8", header = None)
c19w_df5 = pd.read_csv("c19w_df4.csv", encoding = "utf=8")
c19w_df5.head()
c19w_df5.tail()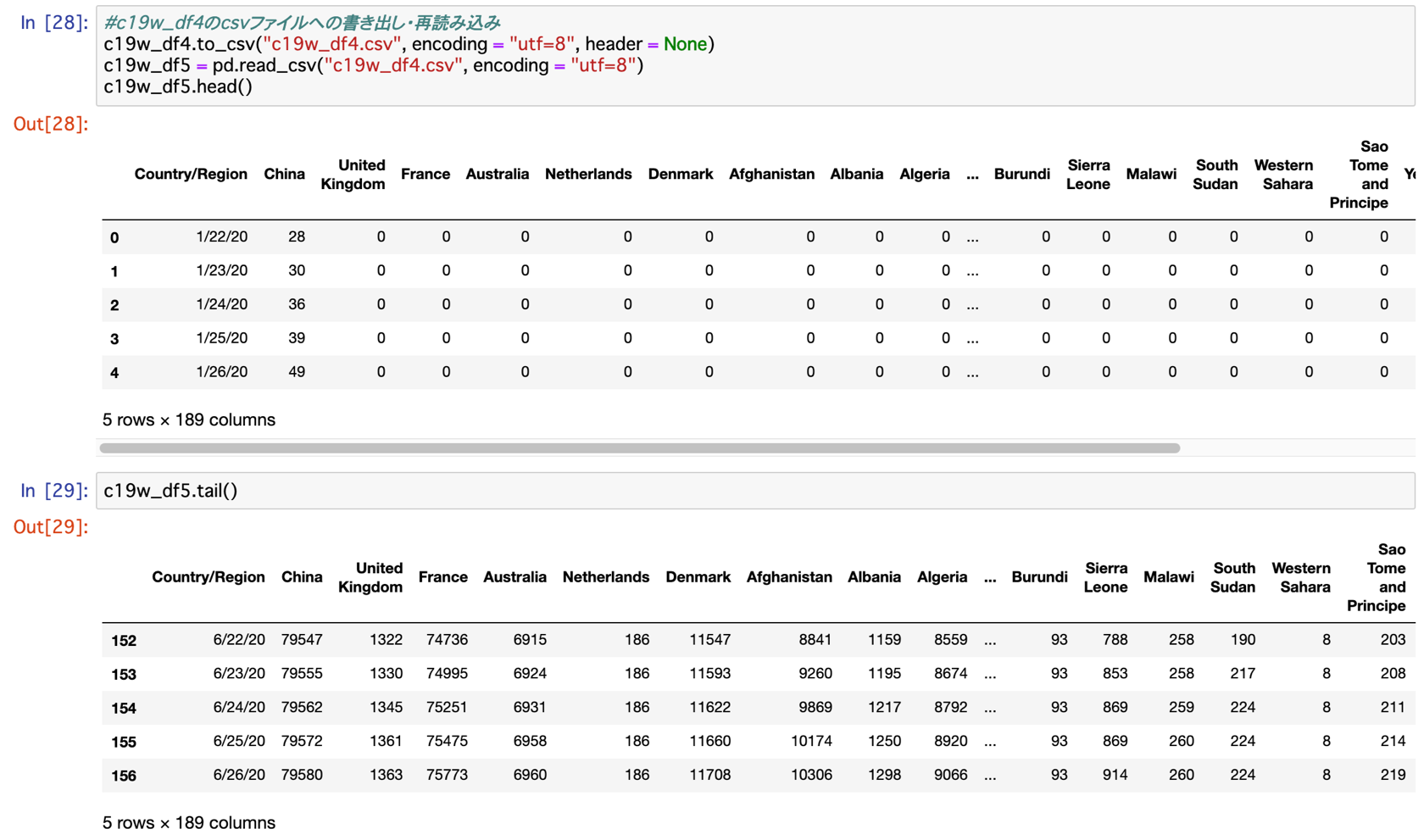
かなり作業が進みましたが、私が求めているデータセットにするには、まだもう一手間必要です。
可視化に必要なデータセットまでもう一息。
気を抜かずに頑張りたいと思います。