前回に引き続き世界版のデータの前処理を続けます。
前回は188カ国分の157日分(2020/01/22〜2020/06/26)のRecovered(回復者)データセットを完成させました。
今回は同じ要領でConfirmed(感染者)、Deaths(死亡者)のデータセットを作成し、最後にマージで横にそれぞれを結合してデータセットc19wを完成させます。
一部の名称を変更するだけで、後は同じ処理を繰り返すだけなので、今回は関数化して処理を行おうと思ったのですが、これは上手くいきませんでした。
ConfirmedとDeathsの元データでは、列Country/Regionに同じ国名が複数行あるデータが、Recoveredと異なっていたからです。
具体的にはRecoveredが6に対し、Confirmed・Deathsでは7ありました。
たった1の違いですが、これが結果に大きく影響します。
また、関数化するには他にもプログラムの変更が多く、現在の私の知識で実現するには問題も多々あり、今回は関数化を断念することになりました。
よって関数化は今後の課題として、今回は先へ進むことにします。
その為、Confirmed・DeathsのデータセットはRecoveredのコードを手直ししてそれぞれ作成することにします。
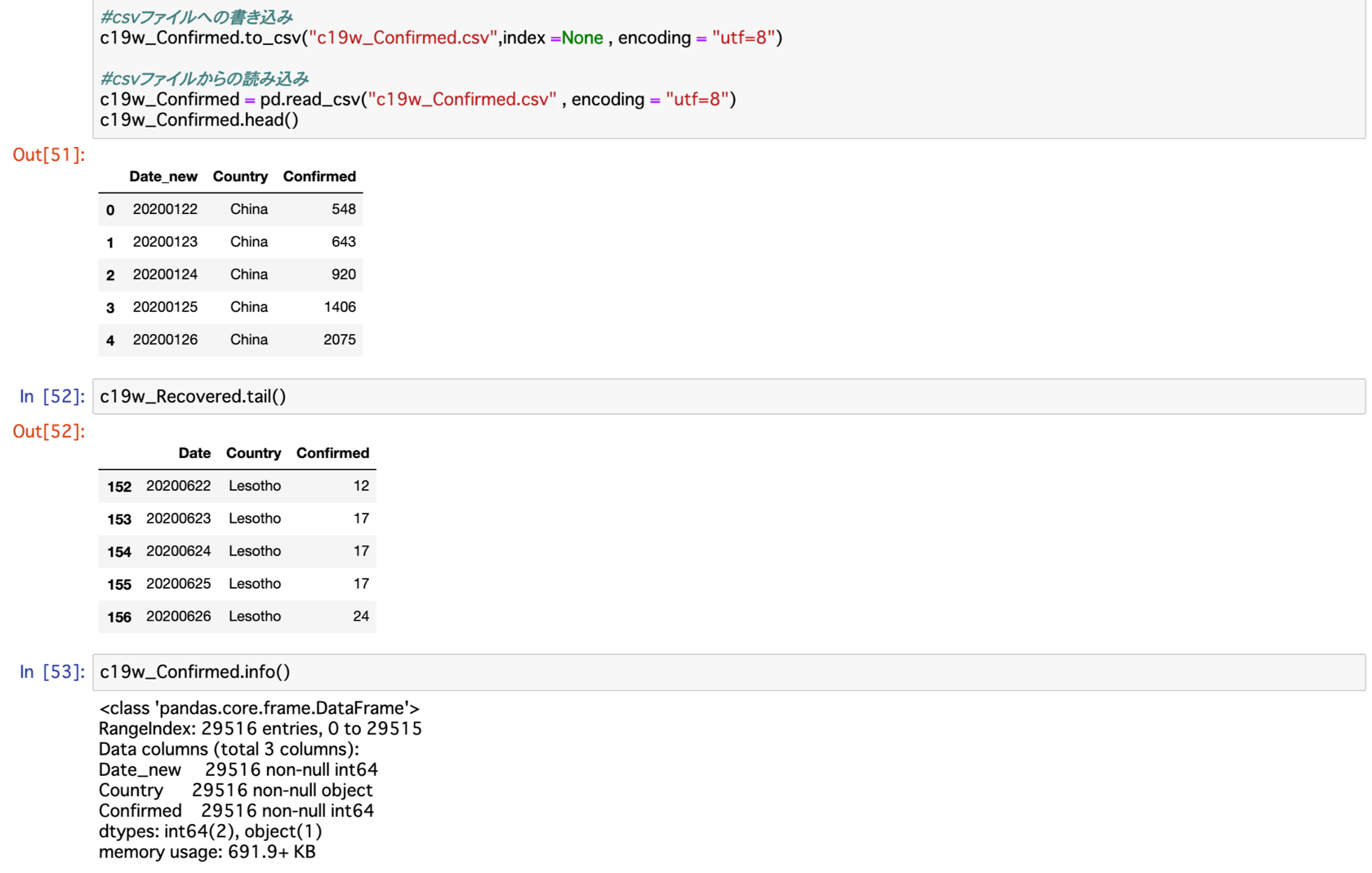
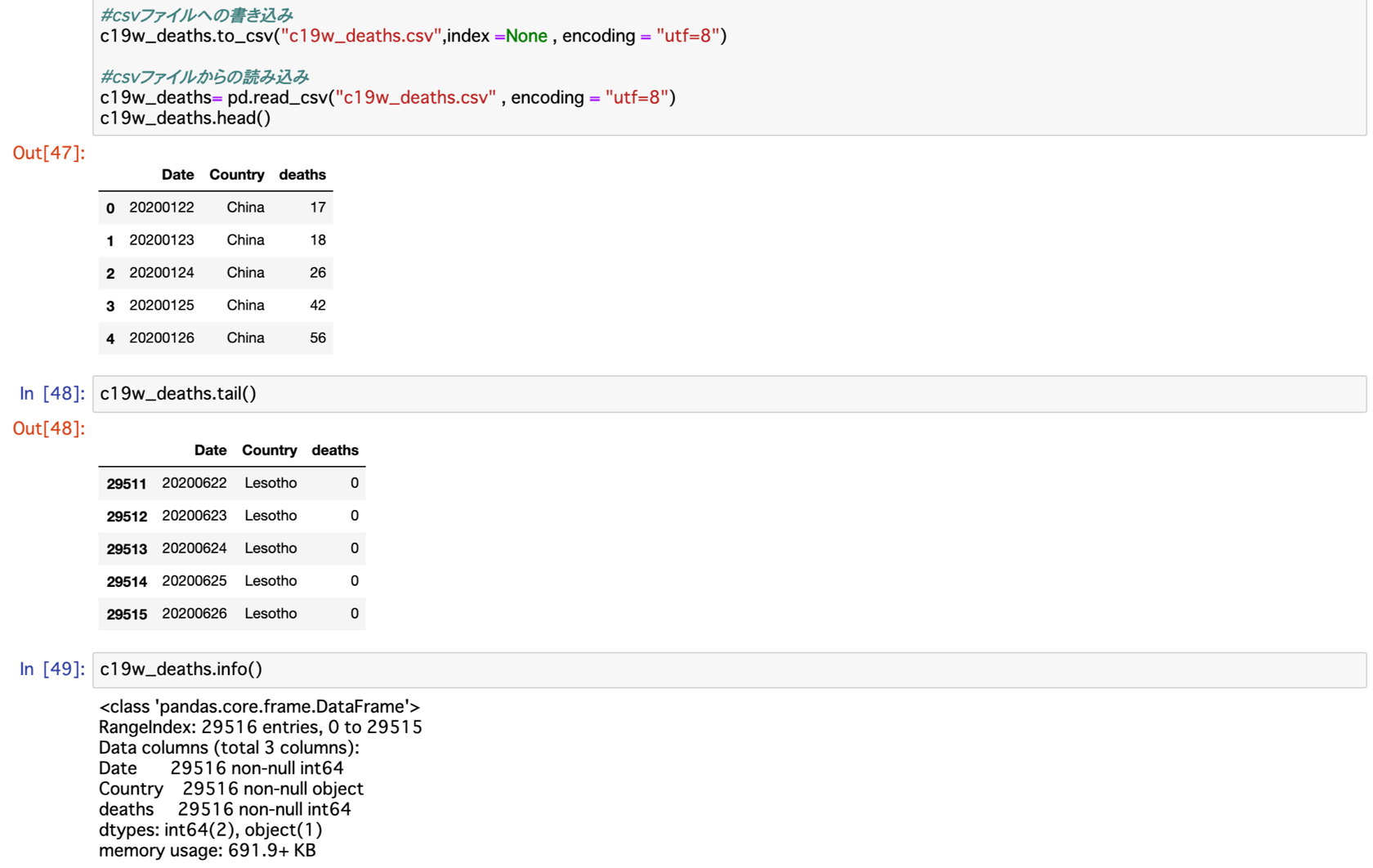
Confirmed・Deaths共に3列・29,516行のデータに無事変換できました。
また、どちらもRecovered同様に2020/01/22のChinaから始まり、2020/06/26のLesothoで終わっています。
Confirmed・Deaths・Recoveredの3つのデータセットが同じ構成になっていることが確認されました。
いよいよデータの結合です。
結合にはmergeを用います。
結合には列Dateと列Countryの二つの列をキーに用います。
国と日付に重複がないので、該当する行が横に結合されるはずです。
まずは各データを読み込みし、データフレームに格納します。
#各データセットの読み込み
c19w_R= pd.read_csv("c19w_Recovered.csv",encoding = "utf-8")
c19w_C= pd.read_csv("c19w_Confirmed.csv",encoding = "utf-8")
c19w_D= pd.read_csv("c19w_Deaths.csv",encoding = "utf-8")
さらにデータフレームの結合を行います。
3つ一気に行う方法が分からなかったので、最初にConfirmedとRecoveredを結合し、さらに出来上がったそのデータセットとDeathsの結合の手順で進めます。
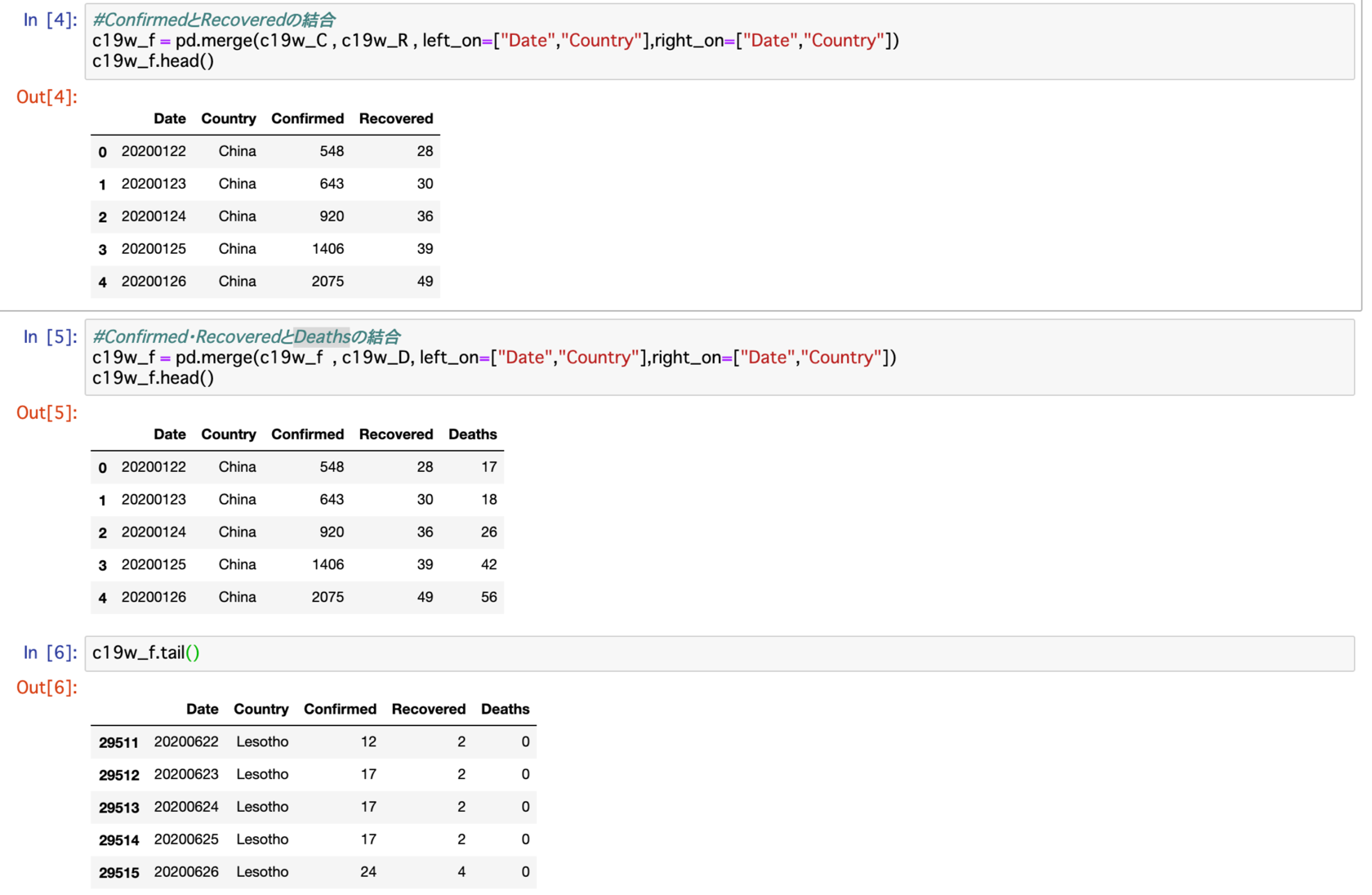
さらにcsvファイルに書き込み・再読み込みを行います
#csvファイルへの書き込み・再読み込み
c19w_f.to_csv("c19w_f.csv" , encoding = "utf-8" , index = None)
c19w_df = pd.read_csv("c19w_f.csv" , encoding = "utf-8" )
c19w_df.head()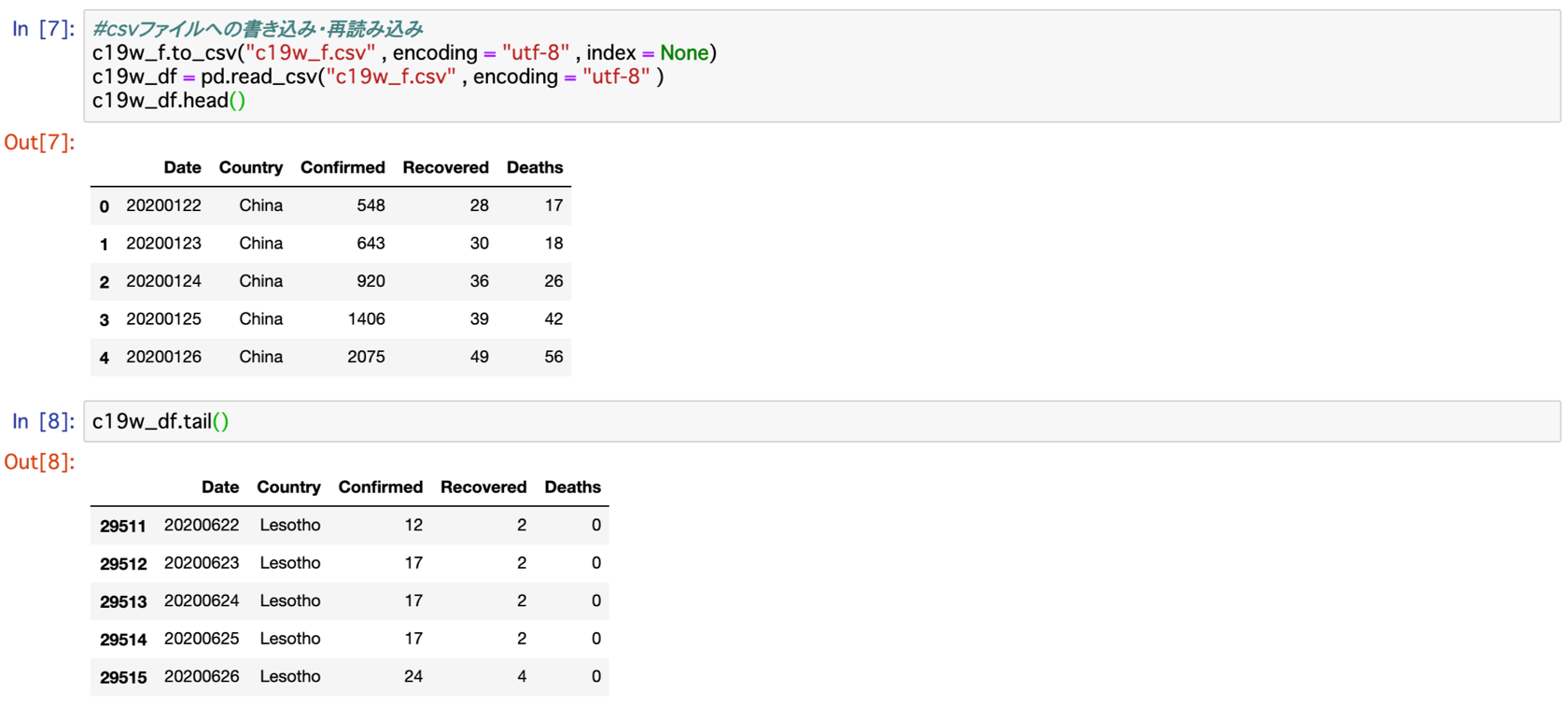
これでデータセットc19w_dfが完成しました。
最後にデータセットの内容を確認して置きます。
問題がなければ、Date・Country・Confirmed・Recovered・Deathsの5列、188カ国×157日分の29,516行のデータセットになっているはずです。
#完成データセットの内容確認
c19w_df.info()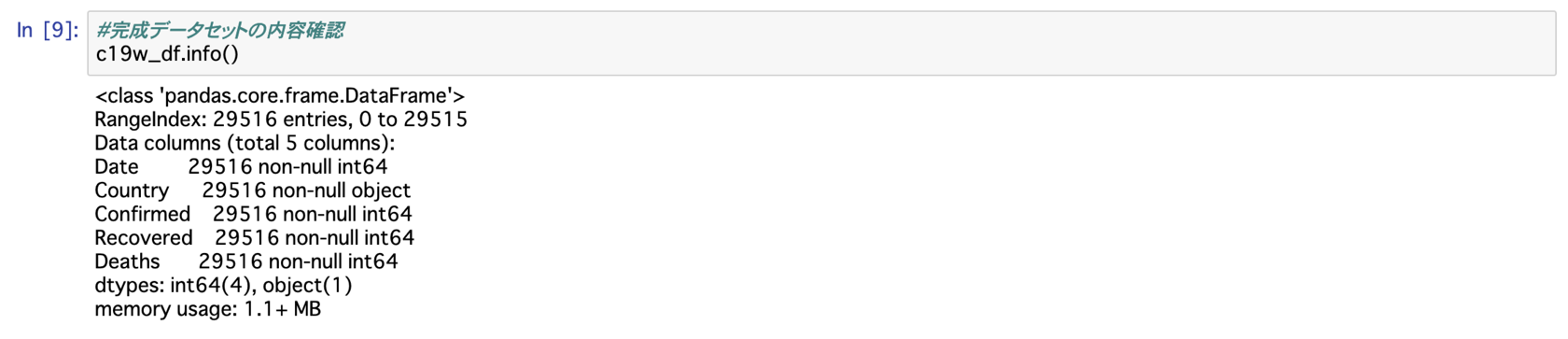
予定通りの内容が表示されました。
これでようやく可視化・分析に取り組めます。
その前にこのデータが最新の元データに対応出来ているかを確認しておく必要があります。
次回は、それを行いたいと思います。